In this how-to guide on the most common queries in MongoDB we will use the sample datasets provided within the MongoDB Atlas installation. Find all the references on how to create a free account on MongoDB Atlas, configure a cluster and load databases to practice in this article.
Cluster connection
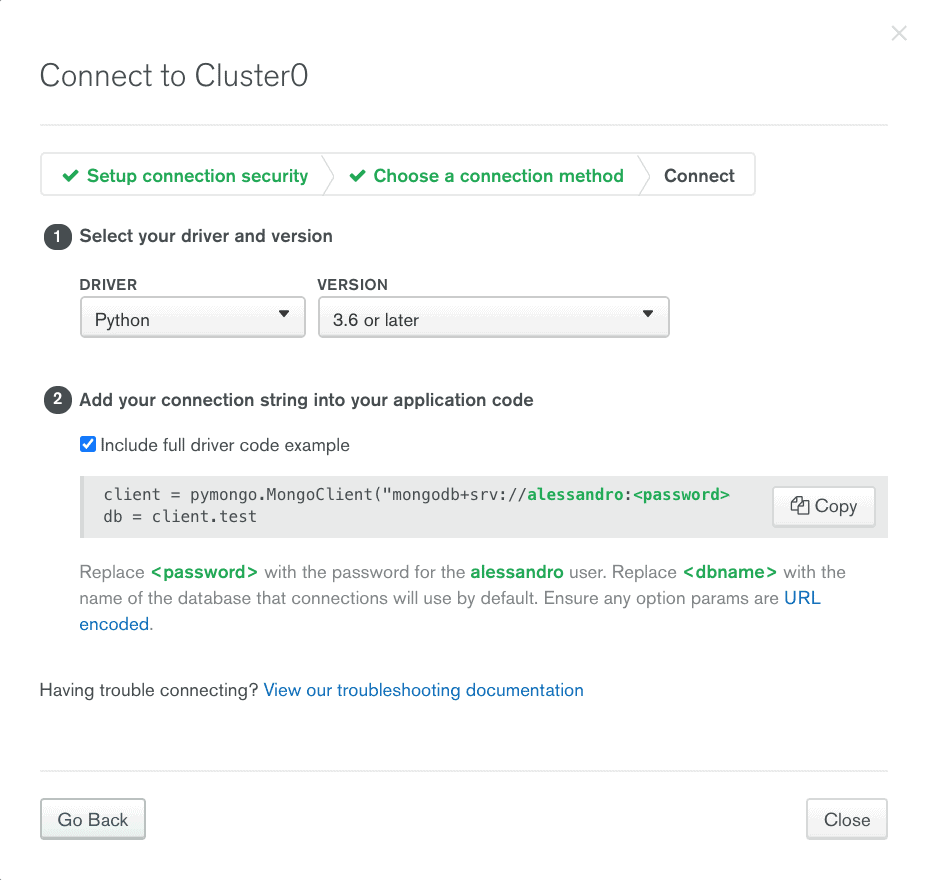
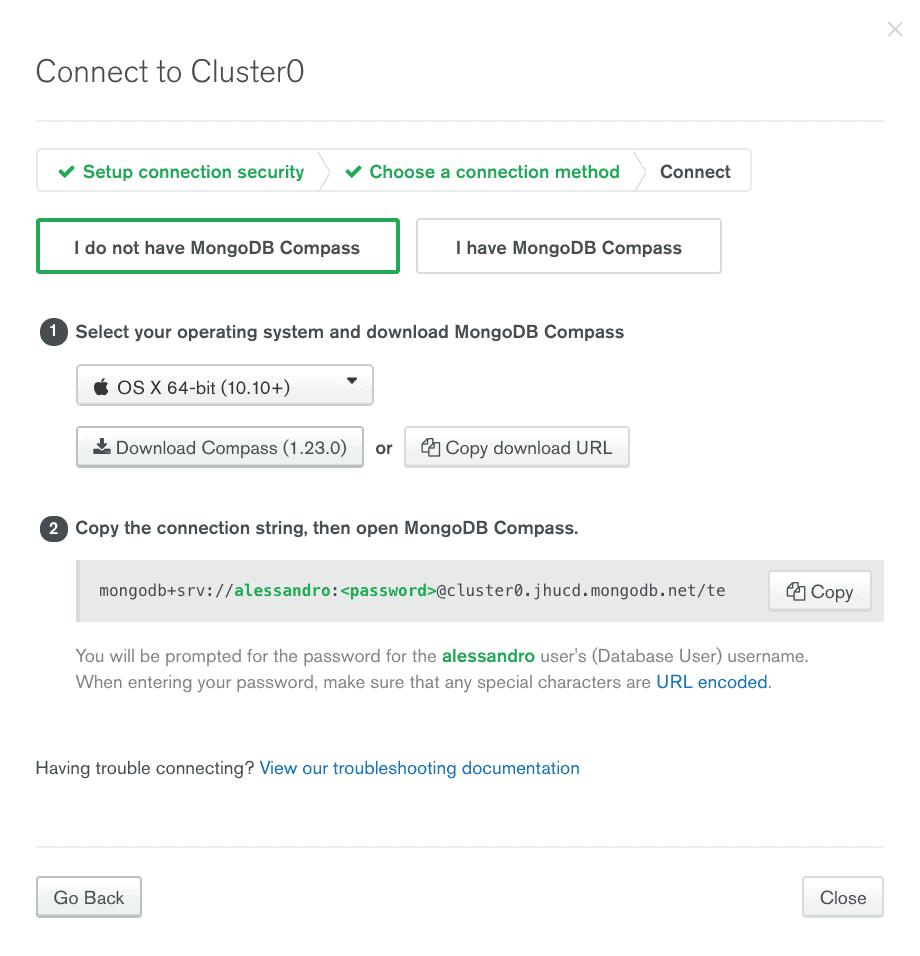
First you need to decide the method of connection to the MongoDB Atlas cluster. Clicking on the CONNECTIONS button will open a popup to choose the method of connection to the cluster. The possible choices are:
- use of the MongoDB shell
- connecting an application using the native MongoDB drivers
- use of MongoDB Compass

According to the choice made the popup will show some basic information to create a secure connection to the cluster. In particular, if you want to use the shell or MongoDB Compass will be shown how to install the necessary software according to the operating system we are using or that we choose. In all cases the connection string to copy will be provided. It will only be necessary to replace the authentication credentials. In the case of a programming language, it is also possible to see an example of code to make the connection to the database. Below are the screenshots for each connection method.
In this guide we’re going to use MongoDB Compass also to evaluate some features that this environment provides.
The MongoDB Compass interface
MongoBD Compass is the standalone software provided by MongoDB to manage and query MongoDB’s NoSQL databases. Obviously it is not possible to create an application that encompasses it, but it can be very useful to extract data, create indexes, analyze the schema of collections and manage document validation.
As soon as you open MongoDB Compass you’ll see an interface to define the connection. To connect to the MongoDB Atlas cluster, simply enter the connection string provided in the previous step, appropriately modified with the login credentials.

It is also possible to enter the various connection options through a special form by clicking on the link “Fill in connection fields individually”. Once the connection is established, the list of available databases in the MongoDB installation will be shown. If you followed the tutorial shown in the article MongoDB Atlas – creating a cloud environment for practice you will find all the example databases provided by MongoDB Atlas.

For each database is shown, in addition to the name, the disk space used, the number of collections and indexes. You can delete a database by simply clicking on the trash can icon next to each database.
If you select a collection of a database from the list on the left side of the screen, the document view will open on the right side. This screen provides a preview of some of the documents contained in the collection and can also be used to write query queries.

The default view is that of the list. If there are complex structures within a document (embedded documents, arrays) it is possible to expand them to display the data present. The other views are the JSON (available since version 1.2) and the tabular view. For each document displayed, you can edit it, copy it to your clipboard, duplicate it and delete it using the buttons on the right associated with each document.
As mentioned earlier, this screen can be used to query the collections. It is possible to insert filters, projections, sort conditions and limitation of the number of records returned. To enter all these options, simply expand the query form by clicking on the OPTIONS button.
Very useful features of the query form are the auto-completion and the syntax validation. As you type, in fact, MongoDB Compass will suggest the fields and operators that might be useful to compose the query. Also, if there is any syntax error the badge next to the form field will have a red colored background.

The second menu is related to aggregation pipelines and is used for more complex queries that require transformation operations of the data present in the documents.
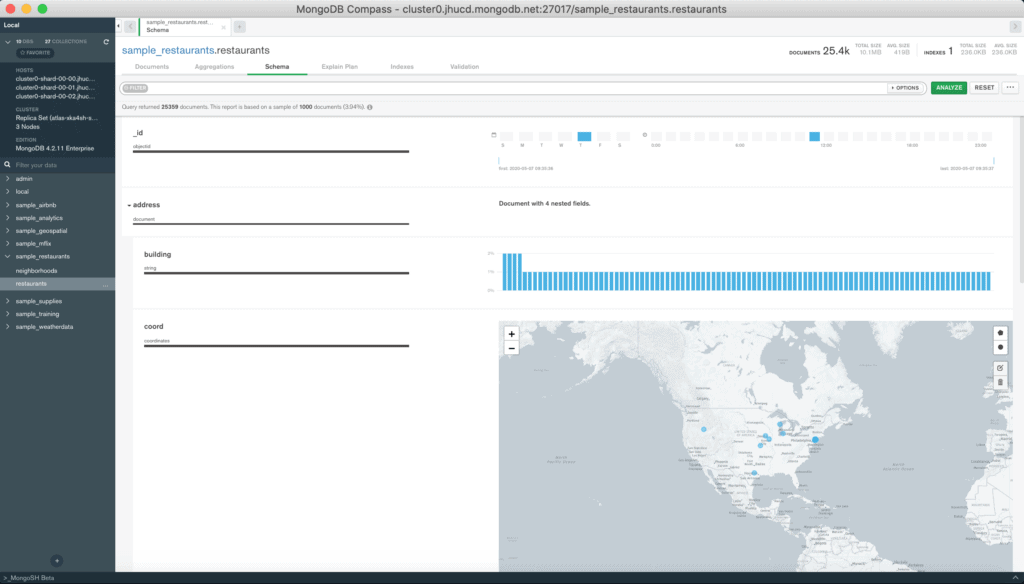
The Schema menu is used to analyze the schema of the data in the collection and retrieve some statistics about the distribution of the data. Next we’ll see how to use it to understand which queries can return results of interest.
The other 3 menus (Explain Plan, Indexes and Validation) will not be used in this tutorial, but are used, as you can see from their names, respectively to analyze the execution plan of a query, manage indexes and insert validation rules for the documents stored in the collection.
Finally, in the upper right part of the screen some information about the number of comments saved, the space occupied both by the collection and on average by each document is always displayed. Information about the indexes defined for the selected collection is also shown.
Querying textual fields
Suppose you want to extract all properties of type “House” from the AirBnB database. In this case you can simply set a filter on the property_type field that is equal to the requested value. The final query will therefore be as follows:
db.listingsAndReviews.find({property_type:"House"}) In MongoDB Compass you simply have to report the filtering condition in the appropriate field indicated by the FILTER tag. In case of syntax errors the label will turn red.
If it is necessary to define which fields should be displayed, order the result or limit the number of documents returned, it is necessary to click on the OPTIONS button to insert these constraints.
The order in which the documents are returned depends on how they are read from disk. If you want to specify a different order, you must enter the SORT option. Also in this case it is required to insert a document that contains the fields on which to perform the sorting. For example if you want to order the result of the previous query according to the increasing price it is sufficient to indicate the following condition:
{price:1} The value 1 indicates an ascending sorting, while -1 indicates a descending sorting. If we wanted to order also according to the date of the last review the condition would result as follows:
{price:1, last_review:-1} As you can see, the two fields are sorted in a different order.
Attention
When sorting is based on multiple attributes, the order is important. In fact, the first attribute indicates the primary sorting, while the following attributes are used only in case of equal value of the previous set of attributes.
Querying numeric fields
For numeric fields you usually use comparison operators to define a desired range. Suppose you want to extract properties that have received more than 100 reviews. The model used for these documents is based on the precomputed model (find more information in this book). As a result, a number_of_reviews field has been defined that indicates the total number of reviews received without counting the items in the reviews vector. Thanks to this model it is possible to answer the previous request in an efficient way simply using the comparison operator $gt.
db.listingsAndReviews.find ( {number_of_reviews: {$gt: 100 } }) Obviously you can define ranges for the same numeric attribute. For example, if you wanted to extract all the properties that have 3 or 4 beds, you can use in combination the operators $gt and $lt as below:
db.listingsAndReviews.find ({beds: {$gt: 2, $lt:5 } }) The exhaustive list of comparison operators is available on the official guide.
Query an array of strings
Each document in the AirBnB database shows the amenities that are available at each property. This information is stored in a vector of strings called amenities. The most classic scenario is to extract for example all the properties that provide Wifi. In this case it is sufficient to set an equality condition for the field of type array. The resulting query will therefore be as follows:
db.listingsAndReviews.find ({amenities:"Wifi"}) You have to be careful though when you want to find all the properties that provide two services such as Wifi and Dryer. Suppose you use the following query:
db.listingsAndReviews.find ({ amenities: ["Wifi", "Dryer"] }) The result will not be as desired. The query will return an empty set since there is no document in the collection that contains only these two services for the amenities attribute. One idea would be to use the $in operator as shown below.
db.listingsAndReviews.find ({ amenities: {$in: ["Wifi", "Dryer"] } }) Also in this case the result will not be the desired one. In fact, all properties that contain at least one of the two services specified in the $in operator will be returned. How then is it possible to specify the coexistence of both services? You have to use the $all operator:
db.listingsAndReviews.find ({ amenities: {$all: ["Wifi", "Dryer"] } }) Nel caso invece le condizioni siano relative a campi diversi è sufficiente mettere in AND i due campi. Ad esempio, se si utilizza il database Mflix e più precisamente la collezione movies, è possibile individuare i film di tipo western in lingua italiana semplicemente con la query seguente:
db.movies.find({genres:"Western", languages:"Italian"}) Attention
String values are case sensitive so pay attention to upper and lower case.
Querying embedded documents
In many cases, the information that is saved has complex structures. Therefore, models based on embedded documents are used. Queries that need to filter data based on specific values on these structures are not very different from the queries seen so far.
Suppose you want to extract all movies that have an imdb rating greater than 8.5, i.e. movies that are deemed by critics as very good movies or great classics. The final query will be
db.movies.find({"imdb.rating": {$gt: 8.5 }}) Attention
To access the fields of an embedded document it is necessary to use the dot notation, but above all to enclose with the " all the path of the desired attribute.
The depth of the document structure does not affect the difficulty of querying. Suppose we want to extract all the theaters that are located in the state of California (CA). Using the theaters collection, we can retrieve this information by accessing the state field of the embedded document address, which in turn is contained in the location field. The query will result as follows:
db.theaters.find({"location.address.state": "CA" }) Querying geographic data
One of the features of MongoDB that makes it one of the most fascinating technological solutions for users is the ability to save geospatial coordinates within a document and query them simply by building an index on them. There is no need to install plugins, extensions or other software to create a geospatial database.
In the example databases uploaded to MongoDB Atlas, spatial indexes are created as the databases are created. For example, in the shipwrecks collection of the sample_geospatial database there is a geospatial index on the coordinates field. You can verify its presence by going to the Indexes menu of MongoDB Compass.

If you wanted to create it, in case it was accidentally not present or was deleted, just type the following command:
db.shipwrecks.createIndex({coordinates: "2dsphere"}) The database being analyzed is for shipwrecks and was built specifically to familiarize you with the use of geospatial data. Since shipwrecks are not found all over the world, defining an exact area of interest may not be so easy. For this reason, the advice is to use the Schema menu to analyze the distribution of the data.

By clicking on the top right ANALYZE button or on the middle one of the Analyze Schema screen, we will see a series of information appear after a few seconds for each field of the documents contained in the collection.
Depending on the type of data distribution the display may be different. If the field takes on data types such as string, double and int, we can change the display by selecting the type of interest. In this way it is possible to understand which are the possible values of a field and how frequent they are.
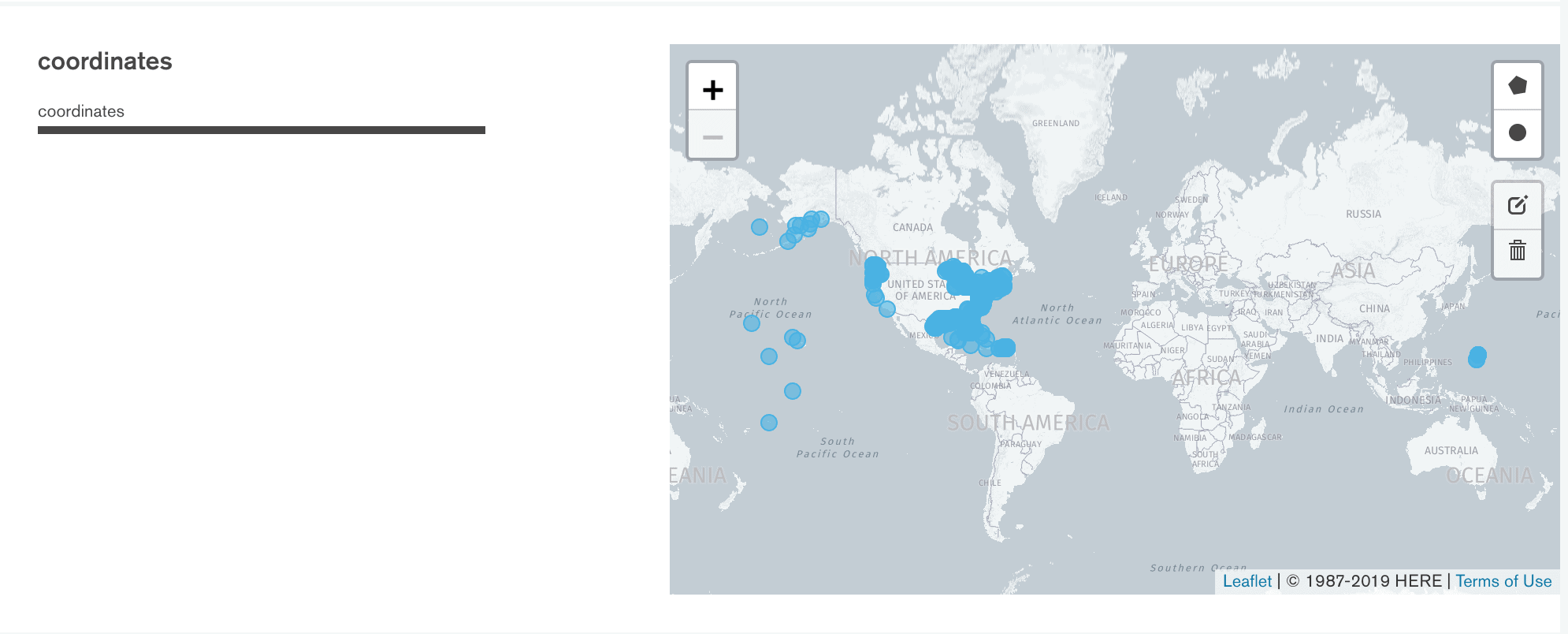
The most interesting representation is that of geospatial fields. In this case, each document is represented on a map that you can navigate. The most useful function, however, is the possibility of defining an area of interest using the commands at the top right of the map.

As soon as the area is drawn, MongoDB Compass reports the filtering condition in the FILTER field at the top. This then allows us to appropriately filter the documents of our interest, but also to perform further analysis on the data distribution of only the selected subset.
Below is an example of a filter obtained using the creation of a circular area of interest.
{coordinates: {$geoWithin:
{ $centerSphere: [
[ -80.79224357496888, 27.574472392552394 ],
0.0903922119472032 ]}
}
} You can also use other operators to query geographic data. You can find a complete list in the official guide.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
2 Responses