
In the construction of applications, one functionality that is always in demand is text search. One only has to browse through the applications one uses on a daily basis such as Amazon, Netflix, Disney+ etc. In all these applications, the search bar is probably the only user interface element common to all of them, and in many cases it is located on the homepage immediately after the header or within the header itself. Therefore, if you are designing an application, you need to think about how to enhance search.
Building a search system is not an easy task, but with Elasticsearch you have a great starting point. In this article, we will discuss what ElasticSearch is, in which contexts it works and in which it does not, and finally, three common projects in which it is used.
What is ElasticSearch?
ElasticSearch is a very popular database that differs from most databases in that it has a powerful search system. Search is so fundamental to ElasticSearch that it is literally in its name!
But if you have never heard of ElasticSearch, you are probably thinking: why is search so difficult? Why can’t a relational database perform a search? Most relational databases support various ways of searching and filtering data, such as constraints in the WHERE clause. Or why can’t a relational database like MongoDB work? Even in MongoDB, it is possible to write search queries.
To understand the answer, imagine you are building a news website. When the user searches for news using the search bar, he is interested in all articles that talk about a certain topic. In a simple search system, this would mean scanning all the articles in the database and returning those that contain the words entered in the search bar. This is not possible with a relational database. A relational database would allow you to search for articles based on specific attributes, e.g. articles written by a particular author or articles published today, etc., but it cannot (at least, not efficiently) perform a search in which it scans every single news article (usually in the tens of millions) and returns those that contain certain words.
Moreover, there are many other complexities to consider. How do you score these articles? Maybe there is an article that talks about artificial intelligence and one that talks about new deep learning algorithms. How do you know which one is the most relevant to the user’s query or, in other words, how do you sort these articles according to relevance?
Answer: ElasticSearch can do all this and much more.
But, like everything else in the world, it has its share of disadvantages. Let us see what ElasticSearch is, when to use it and, above all, when it does not make sense.
Search capability
ElasticSearch offers a way to perform a ‘full-text search’. Full-text search refers to searching for a phrase or word in a huge corpus of documents. Let us continue with the previous example: let us imagine building a news website that contains millions of articles. Each article contains certain data, such as a title, a subtitle, the content of the article, the publication date, etc. In the context of ElasticSearch, each article is stored as a JSON document.
You can load all these documents into ElasticSearch and then search for specific words or phrases within each of these documents in milliseconds. Thus, if you load all the news articles and search for “COVID19 infections in Delhi”, ElasticSearch returns all articles that contain the words “COVID19”, “infections” or “Delhi”.
To demonstrate the search in ElasticSearch, we configure ElasticSearch and load some data. For this article, we will use this news dataset available on Kaggle. The dataset is quite simple: it contains about 210,000 news articles, with their titles, short descriptions, authors and some other fields that we do not care much about.
These are some examples of documents in the dataset.
[
{
"link": "https://www.huffpost.com/entry/new-york-city-board-of-elections-mess_n_60de223ee4b094dd26898361",
"headline": "Why New York City’s Board Of Elections Is A Mess",
"short_description": "“There’s a fundamental problem having partisan boards of elections,” said a New York elections attorney.",
"category": "POLITICS",
"authors": "Daniel Marans"
},
....
]
Each document represents a news article. Each article contains a link, a title, a short description, a category and the authors.
Elasticsearch queries are written in JSON. Instead of delving into all the different syntaxes that can be used to create search queries, let’s start simple and go from there.
One of the simplest full-text queries is the multi_match query. The idea is simple: you write a query and Elasticsearch performs a full-text search, essentially scanning all the documents in the database, finding those that contain the words in the query, scoring them and returning them. For example,
GET news/_search
{
"query": {
"multi_match": {
"query": "COVID19 infections"
}
}
}
The above search finds relevant articles for the query “COVID19 infections”. These are the results
[
{
"_index" : "news",
"_id" : "czrouIsBC1dvdsZHkGkd",
"_score" : 8.842152,
"_source" : {
"link" : "https://www.huffpost.com/entry/china-shanghai-lockdown-coronavirus_n_62599aa1e4b0723f8018b9c2",
"headline" : "Strict Coronavirus Shutdowns In China Continue As Infections Rise",
"short_description" : "Access to Guangzhou, an industrial center of 19 million people near Hong Kong, was suspended this week.",
"category" : "WORLD NEWS",
"authors" : "Joe McDonald, AP"
}
},
{
"_index" : "news",
"_id" : "ODrouIsBC1dvdsZHlmoc",
"_score" : 8.064016,
"_source" : {
"link" : "https://www.huffpost.com/entry/who-covid-19-pandemic-report_n_6228912fe4b07e948aed68f9",
"headline" : "COVID-19 Cases, Deaths Continue To Drop Globally, WHO Says",
"short_description" : "The World Health Organization said new infections declined by 5 percent in the last week, continuing the downward trend in COVID-19 infections globally.",
"category" : "WORLD NEWS",
"authors" : "",
}
},
....
]
As can be seen, it returns documents dealing with COVID19 infections. It also returns them sorted in order of relevance (the _score field indicates how relevant a particular document is).
ElasticSearch has a feature-rich query language, but for the time being, it is enough to know that building a simple search system is very easy, just load all the data into ElasticSearch and use a simple query as we have seen in this example. There are a plethora of options to improve, configure and modify the performance and relevance of the search.
Distributed architecture
ElasticSearch works as a distributed database, like most NoSQL databases. This means that there are multiple nodes in a single ElasticSearch cluster. If a single node becomes unavailable or fails, this usually does not mean a system outage and the other nodes usually pick up the extra work and continue to serve user requests. Thus, multiple nodes facilitate higher availability.
Multiple nodes also help us to scale systems: data and user requests can be divided between these nodes, which means less load for each node. For example, if you want to store 100 million news articles in ElasticSearch, you can split the data into multiple nodes, with each node storing a specific set of articles. This is quite easy to do, as ElasticSearch has built-in functions to make this operation as simple as possible.
This aspect is horizontal scalability! This means that query performance can always be improved by adding more nodes to the ElasticSearch cluster.
Document-based modelling
ElasticSearch is a document database, which stores data in JSON format, similar to MongoDB. Thus, in our example, each news article is stored as a JSON document in the cluster. Unlike MongoDB, it is not possible to apply all the modelling patterns we described in the book “Design with MongoDB: Best models for applications” due to certain limitations imposed on us by Elasticsearch itself. Some, however, are worth considering in order to appropriately model the documents we wish to store in the database.
Real-time analysis
Real-time data analysis consists of observing events that are captured by the system and defining patterns of behaviour and/or anomalies in the data flow. We can, for example, track users’ behaviour and understand them better, thus improving our product. Suppose we measure every single click, scroll event and reading time per user on our news website. By visualising these metrics in a dashboard, we can extrapolate a lot of useful information to improve our application. We might discover that users usually use the website in a certain time slot in the morning and that they generally click on articles relevant to their country. Using this information, we can provide more news during peak hours and perhaps display articles according to the country of the connected user.
Elasticsearch is suitable for real-time data analysis due to its distributed architecture and powerful search capabilities. When it comes to real-time data, such as logs, metrics or social media updates, Elasticsearch efficiently indexes and archives this information. Near real-time indexing allows data to be searched almost instantaneously after ingestion. ElasticSearch also works well with other tools, such as Kibana for visualisation or Logstash and Beats for metrics collection.
When not to use Elasticsearch
ACID Operations Request
ElasticSearch, like most NoSQL databases, has very limited support for ACID functionality. So if you want strong consistency or transactional support, ElasticSearch may not be the right database. The consequences of this are that if you insert a document into ElasticSearch, it may not be immediately available to other nodes and may take several milliseconds before it is visible to other nodes.
Suppose you are building a banking system; if a user deposits money into his account, you want that data to be immediately visible to all other transactions that the user performs. On the other hand, if you are using ElasticSearch to power searches on your news website when a new article is published, it is probably acceptable that the article is not visible to all users for the first few milliseconds.
When complex joins are needed
ElasticSearch does not support JOIN operations or relationships between different tables. If you have been using relational databases, this might come as a bit of a shock to you, but most NoSQL databases have limited support for this type of operation.
If you want to perform JOIN operations or use foreign keys for highly correlated structured data, ElasticSearch may not be the best choice for your use case.
Small datasets or simple query needs
ElasticSearch is complex to manage and maintain. Running and managing a large ElasticSearch cluster not only requires the knowledge and skill of software engineers and DevOps, but may even require specialists who excel in ElasticSearch cluster management and architecture. There is a plethora of configuration options and architectural choices to play with and each of them has a significant impact on queries and ingestion, indirectly impacting the user experience in the main system flows.
If you want to perform simple queries or have a relatively small amount of data, then a simple database may be more suitable for your application.
How to use ElasticSearch in system design
A single software system usually requires several databases, each feeding a different set of functionalities. Let us take an example to better understand the design choices of using ElasticSearch.
Suppose we want to build a video streaming service, such as Netflix or Disney+. Let us see where ElasticSearch can be used in this example.
As search system
A very common use case of ElasticSearch is as a secondary database that feeds full-text search queries. This is very useful for our video streaming application. We cannot store videos in ElasticSearch and probably do not want to store billing or user data in ElasticSearch either.
For this, we can have other databases, but we can store the titles of the films, together with their description, genres, ratings, etc. in ElasticSearch.
We could have an architecture similar to this:

We can enter the data on which we want to perform a full-text search into ElasticSearch. When the user performs a search operation, we can query the ElasticSearch cluster. In this way we obtain the full-text search functionality of ElasticSearch and when we want to update the user’s information, we can perform the updates in our primary database.
As real-time data analysis pipeline
As we said, understanding user behaviour is a key aspect in deciding how to evolve our service.
For example, in our video streaming application, we could save events with user data and movies every time a user clicks on a film or show. We can then analyse these through dashboards to better understand how users use our product. For example, we might notice that users use our product more in the evening than in the afternoon or that they prefer shows or films in their local language over other languages. Based on this, we can develop our product to improve the user experience.
This is how a system for real-time data analysis could be structured using ElasticSearch and Kibana.
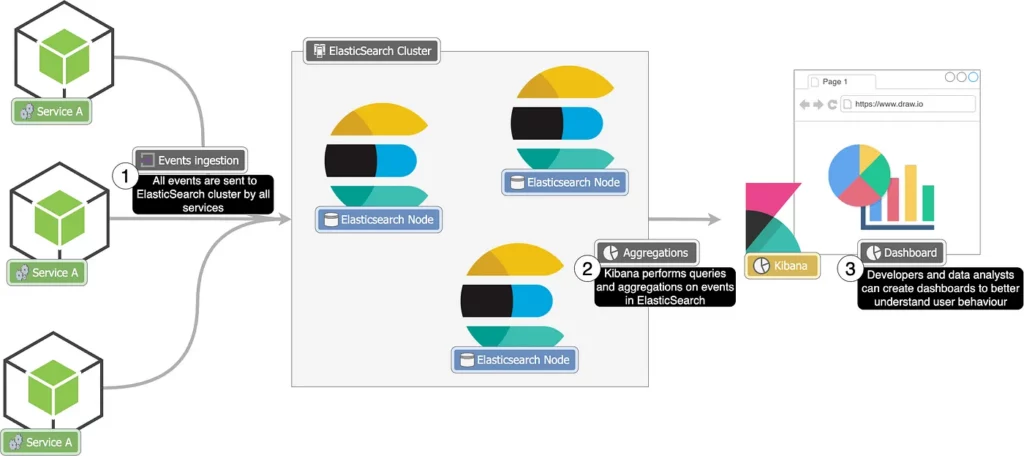
As a recommendation system
In ElasticSearch, it is possible to construct queries that give greater preference to certain attributes. By storing some information about the user, such as country, age, preferences and so on, we could generate queries to get popular films or series for that user by weighting certain fields more heavily.
Conclusion
How to design ElasticSearch clusters?
The architecture of an ElasticSearch cluster is not an easy undertaking: it requires knowledge of nodes, shards, indexes and how to orchestrate them all. The architectural choices to be made are almost endless and the field is constantly evolving (especially with the popularity of artificial intelligence and AI-powered search). There are many articles and books on the subject, in addition to the official Elasticsearch documentation.
Understanding search queries and improving search systems
Search is complex by definition. There are many ways to improve search systems, making them more powerful and able to understand users’ needs. If you would like to learn how to query Elasticsearch, you can explore the articles here.
Context-aware search
In many contexts, search must not only be textual but also semantic. Semantic search is a set of search techniques that aims to understand the meaning of users’ queries and the context of the content, enabling more accurate and contextually relevant search results by considering the relationships between words and the intent behind the search. Think about going to the bookstore and searching for a book on a certain topic. The shopkeeper will carefully assess our request by also evaluating other aspects, such as what we need, the age of the reader, etc. This aspect must be considered when designing advanced systems.


