
Nella costruzione di applicazioni una funzionalità sempre richiesta è la ricerca testuale. Basta navigare nelle applicazioni che si usano quotidianamente come Amazon, Netflix, Disney+ ecc. In tutte queste applicazioni la barra di ricerca è probabilmente l’unico elemento dell’interfaccia utente comune a tutte, e in molti casi si trova nella homepage subito dopo l’header o all’interno dello stesso. Pertanto, se state progettando un’applicazione, dovete pensare a come potenziare la ricerca.
Costruire un sistema di ricerca non è un’impresa semplice, ma con Elasticsearch avete a disposizione un ottimo punto di partenza. In questo articolo parleremo di cos’è ElasticSearch, in quali contesti funziona e in quali no, e, infine, di tre progetti comuni in cui viene utilizzato.
Che cos’è ElasticSearch?
ElasticSearch è un database molto popolare che si differenzia dalla maggior parte dei database in quanto ha un potente sistema di ricerca. La ricerca è così fondamentale per ElasticSearch che è letteralmente nel suo nome!
Ma se non avete mai sentito parlare di ElasticSearch, probabilmente starete pensando: perché la ricerca è così difficile? Perché un database relazionale non può eseguire una ricerca? La maggior parte dei database relazionali supporta vari modi per cercare e filtrare i dati, come i vincoli nella clausola WHERE. Oppure perché un database documentale come MongoDB non può funzionare? Anche in MongoDB è possibile scrivere query di ricerca.
Per capire la risposta, immaginate di costruire un sito web di notizie. Quando l’utente cerca notizie utilizzando la barra di ricerca è interessato a tutti gli articoli che parlano di un determinato argomento. In un sistema di ricerca semplice, ciò significherebbe scansionare tutti gli articoli del database e restituire quelli che contengono le parole inserite nella barra di ricerca. Non è possibile farlo con un database relazionale. Un database relazionale permetterebbe di cercare articoli in base ad attributi specifici, ad esempio articoli scritti da un particolare autore o articoli pubblicati oggi, ecc. ma non può (almeno, non in modo efficiente) eseguire una ricerca in cui scansiona ogni singolo articolo di notizie (di solito in decine di milioni) e restituire quelli che contengono determinate parole.
Inoltre, ci sono molte altre complessità da considerare. Come si fa a dare un punteggio a questi articoli? Magari c’è un articolo che parla dell’intelligenza artificiale e uno che parla di nuovi algoritmi di deep learning. Come si fa a sapere qual è quello più rilevante per la richiesta dell’utente o, in altre parole, come si ordinano questi articoli in base alla rilevanza?
Risposta: ElasticSearch è in grado di fare tutto questo e molto di più.
Ma, come ogni altra cosa al mondo, ha la sua parte di svantaggi. Vediamo cos’è ElasticSearch, quando usarlo e, soprattutto, quando non ha senso.
Capacità di ricerca
ElasticSearch offre un modo per eseguire una “ricerca full-text”. La ricerca full-text si riferisce alla ricerca di una frase o di una parola in un enorme corpus di documenti. Continuiamo con l’esempio precedente: immaginiamo di costruire un sito web di notizie che contiene milioni di articoli. Ogni articolo contiene alcuni dati, come un titolo, un sottotitolo, il contenuto dell’articolo, la data di pubblicazione, ecc. Nel contesto di ElasticSearch, ogni articolo è memorizzato come documento JSON.
È possibile caricare tutti questi documenti in ElasticSearch e quindi cercare parole o frasi specifiche all’interno di ciascuno di questi documenti in pochi millisecondi. Quindi, se si caricano tutti gli articoli di notizie e si esegue la ricerca “COVID19 infezioni a Delhi”, ElasticSearch restituisce tutti gli articoli che contengono le parole “COVID19”, “infezioni” o “Delhi”.
Per dimostrare la ricerca in ElasticSearch, configuriamo Elasticsearch e carichiamo alcuni dati. Per questo articoli, utilizzeremo questo dataset di notizie disponibile su Kaggle. Il dataset è piuttosto semplice: contiene circa 210.000 articoli di notizie, con i loro titoli, le brevi descrizioni, gli autori e alcuni altri campi di cui non ci importa molto.
Questi sono alcuni esempi di documenti presenti nel dataset.
[
{
"link": "https://www.huffpost.com/entry/new-york-city-board-of-elections-mess_n_60de223ee4b094dd26898361",
"headline": "Why New York City’s Board Of Elections Is A Mess",
"short_description": "“There’s a fundamental problem having partisan boards of elections,” said a New York elections attorney.",
"category": "POLITICS",
"authors": "Daniel Marans"
},
....
]
Ogni documento rappresenta un articolo di cronaca. Ogni articolo contiene un link, un titolo, una breve descrizione, una categoria e gli autori.
Le query di Elasticsearch sono scritte in JSON. Invece di addentrarci in tutte le diverse sintassi che si possono usare per creare query di ricerca, iniziamo in modo semplice e partiamo da lì.
Una delle query full-text più semplici è la query multi_match. L’idea è semplice: si scrive una query ed Elasticsearch che esegue una ricerca full-text, scansionando essenzialmente tutti i documenti del database, trovando quelli che contengono le parole della query, assegnando loro un punteggio e restituendoli. Ad esempio,
GET news/_search
{
"query": {
"multi_match": {
"query": "COVID19 infections"
}
}
}
La ricerca di cui sopra trova articoli rilevanti per la query “infezioni da COVID19”. Questi sono i risultati che si possono ottenere
[
{
"_index" : "news",
"_id" : "czrouIsBC1dvdsZHkGkd",
"_score" : 8.842152,
"_source" : {
"link" : "https://www.huffpost.com/entry/china-shanghai-lockdown-coronavirus_n_62599aa1e4b0723f8018b9c2",
"headline" : "Strict Coronavirus Shutdowns In China Continue As Infections Rise",
"short_description" : "Access to Guangzhou, an industrial center of 19 million people near Hong Kong, was suspended this week.",
"category" : "WORLD NEWS",
"authors" : "Joe McDonald, AP"
}
},
{
"_index" : "news",
"_id" : "ODrouIsBC1dvdsZHlmoc",
"_score" : 8.064016,
"_source" : {
"link" : "https://www.huffpost.com/entry/who-covid-19-pandemic-report_n_6228912fe4b07e948aed68f9",
"headline" : "COVID-19 Cases, Deaths Continue To Drop Globally, WHO Says",
"short_description" : "The World Health Organization said new infections declined by 5 percent in the last week, continuing the downward trend in COVID-19 infections globally.",
"category" : "WORLD NEWS",
"authors" : "",
}
},
....
]
Come si può vedere, restituisce i documenti che trattano le infezioni da COVID19. Inoltre, li restituisce ordinati in ordine di rilevanza (il campo _score indica quanto è rilevante un particolare documento).
ElasticSearch ha un linguaggio di interrogazione ricco di funzioni, ma per il momento è sufficiente sapere che costruire un semplice sistema di ricerca è molto facile, basta caricare tutti i dati in ElasticSearch e usare una semplice query come abbiamo visto in questo esempio. Esistono una pletora di opzioni per migliorare, configurare e modificare le prestazioni e la pertinenza della ricerca.
Architettura distribuita
ElasticSearch funziona come un database distribuito, come la maggior parte dei database NoSQL. Ciò significa che ci sono più nodi in un singolo cluster ElasticSearch. Se un singolo nodo diventa indisponibile o si guasta, ciò non significa di solito un’interruzione del sistema e gli altri nodi di solito raccolgono il lavoro extra e continuano a servire le richieste degli utenti. Quindi più nodi facilitano una maggiore disponibilità.
I nodi multipli ci aiutano anche a scalare i sistemi: i dati e le richieste degli utenti possono essere suddivisi tra questi nodi, il che comporta un minor carico per ciascun nodo. Ad esempio, se si desidera memorizzare 100 milioni di articoli di notizie in ElasticSearch, è possibile suddividere i dati in più nodi, con ciascun nodo che memorizza un determinato set di articoli. È piuttosto facile da fare, infatti ElasticSearch è dotato di funzioni integrate per rendere questa operazione il più semplice possibile.
Questo aspetto è la scalabilità orizzontale! Ciò significa che è sempre possibile migliorare le prestazioni delle query aggiungendo altri nodi al cluster ElasticSearch.
Modellazione basata sui documenti
ElasticSearch è un database di documenti, che memorizza i dati in formato JSON, simile a MongoDB. Quindi, nel nostro esempio, ogni articolo di notizie viene memorizzato come documento JSON nel cluster. A differenza di MongoDB, non è possibile applicare tutti i pattern di modellazione che abbiamo descritto nel libro “Progettare con MongoDB: I migliori modelli per le applicazioni” a causa di alcune limitazioni che ci impone lo stesso Elasticsearch. Alcuni, però, sono da considerare per modellare opportunamente i documenti che vogliamo salvare nel database.
Analisi real-time
L’analisi dei dati in tempo reale consiste nell’osservare gli eventi che vengono catturati dal sistema e nel definire modelli di comportamento e/o anomalie nel flusso dei dati. Possiamo, ad esempio, tracciare il comportamento degli utenti e comprenderli meglio, migliorando così il nostro prodotto. Supponiamo di misurare ogni singolo clic, evento di scorrimento e tempo di lettura per utente sul nostro sito web di notizie. Visualizzando queste metriche in una dashboard, possiamo estrapolare molte informazioni utili per migliorare la nostra applicazione. Potremmo scoprire che gli utenti utilizzano il sito web di solito in una determinata fascia oraria del mattino e che in genere cliccano su articoli rilevanti per il loro Paese. Utilizzando queste informazioni, possiamo fornire maggiori notizie durante le ore di punta e magari mostrare gli articoli in base al paese dell’utente collegato.
Elasticsearch è adatto all’analisi dei dati in tempo reale grazie alla sua architettura distribuita e alle sue potenti capacità di ricerca. Quando si tratta di dati in tempo reale, come log, metriche o aggiornamenti dei social media, Elasticsearch indicizza e archivia in modo efficiente queste informazioni. L’indicizzazione quasi in tempo reale consente di ricercare i dati quasi istantaneamente dopo l’ingestione. ElasticSearch funziona bene anche con altri strumenti, come Kibana per la visualizzazione o Logstash e Beats per la collezione di metriche.
Quando non usare Elasticsearch
Richiesta di operazioni ACID
ElasticSearch, come la maggior parte dei database NoSQL, ha un supporto molto limitato per le funzionalità ACID. Quindi se si desidera una forte coerenza o un supporto transazionale, ElasticSearch potrebbe non essere il database adatto. Le conseguenze di ciò sono che se si inserisce un documento in ElasticSearch, questo potrebbe non essere immediatamente disponibile per gli altri nodi e potrebbe richiedere alcuni millisecondi prima di essere visibile agli altri nodi.
Supponiamo che stiate costruendo un sistema bancario; se un utente deposita del denaro sul suo conto, volete che quel dato sia immediatamente visibile a tutte le altre transazioni che l’utente esegue. D’altra parte, se state usando ElasticSearch per alimentare le ricerche sul vostro sito web di notizie quando viene pubblicato un nuovo articolo, è probabilmente accettabile che l’articolo non sia visibile a tutti gli utenti per i primi millisecondi.
Quando servono join complessi
ElasticSearch non supporta le operazioni di JOIN o le relazioni tra tabelle diverse. Se avete usato database relazionali, questo potrebbe essere un po’ uno shock per voi, ma la maggior parte dei database NoSQL ha un supporto limitato per questo tipo di operazioni.
Se volete eseguire JOIN o utilizzare chiavi esterne per dati strutturati altamente correlati, ElasticSearch potrebbe non essere la scelta migliore per il vostro caso d’uso.
Piccoli set di dati o semplici esigenze di query
ElasticSearch è complesso da gestire e mantenere. L’esecuzione e la gestione di un cluster ElasticSearch di grandi dimensioni non solo richiede la conoscenza e l’abilità di ingegneri software e DevOps, ma potrebbe addirittura richiedere specialisti che eccellono nella gestione e nell’architettura di cluster ElasticSearch. Esiste una pletora di opzioni di configurazione e di scelte architetturali con cui giocare e ognuna di esse ha un impatto significativo sulle query e sull’ingestion, con un impatto indiretto sull’esperienza dell’utente nei flussi principali del sistema.
Se si desidera eseguire query semplici o avere un numero relativamente basso di dati, allora un database semplice potrebbe essere più adatto alla vostra applicazione.
Come utilizzare ElasticSearch nella progettazione di un sistema
Un singolo sistema software di solito richiede più database, ognuno dei quali alimenta un diverso insieme di funzionalità. Facciamo un esempio per capire meglio le scelte progettuali dell’utilizzo di ElasticSearch.
Supponiamo di voler costruire un servizio di streaming video, come Netflix o Disney+. Vediamo dove ElasticSearch può essere utilizzato in questo esempio.
Come sistema di ricerca
Un caso d’uso molto comune di ElasticSearch è quello di database secondario che alimenta le query di ricerca full-text. Questo è molto utile per la nostra applicazione di streaming video. Non possiamo memorizzare i video in ElasticSearch e probabilmente non vogliamo memorizzare in ElasticSearch anche i dati relativi alla fatturazione o agli utenti.
Per questo, possiamo avere altri database, ma possiamo memorizzare i titoli dei film, insieme alla loro descrizione, ai generi, alle valutazioni, ecc. in ElasticSearch.
Potremmo avere un’architettura simile a questa:

Possiamo inserire in ElasticSearch i dati su cui vogliamo effettuare una ricerca full-text. Quando l’utente esegue un’operazione di ricerca, possiamo interrogare il cluster ElasticSearch. In questo modo otteniamo le funzionalità di ricerca full-text di ElasticSearch e quando vogliamo aggiornare le informazioni dell’utente, possiamo eseguire gli aggiornamenti nel nostro database primario.
Come pipeline di analisi dei dati in tempo reale
Come abbiamo detto, la comprensione del comportamento degli utenti è un aspetto fondamentale per decidere come far evolvere il nostro servizio.
Ad esempio, nella nostra applicazione di streaming video, potremmo salvare gli eventi con i dati degli utenti e dei filmati ogni volta che un utente clicca su un film o su uno spettacolo. Possiamo poi analizzarli mediante delle dashboard per capire meglio come gli utenti utilizzano il nostro prodotto. Ad esempio, potremmo notare che gli utenti utilizzano il nostro prodotto più la sera che il pomeriggio o che preferiscono gli spettacoli o i film nella loro lingua locale rispetto ad altre lingue. In base a ciò, possiamo sviluppare il nostro prodotto per migliorare l’esperienza dell’utente.
Ecco come si potrebbe essere strutturato un sistema per l’analisi dei dati in tempo reale utilizzando ElasticSearch e Kibana.
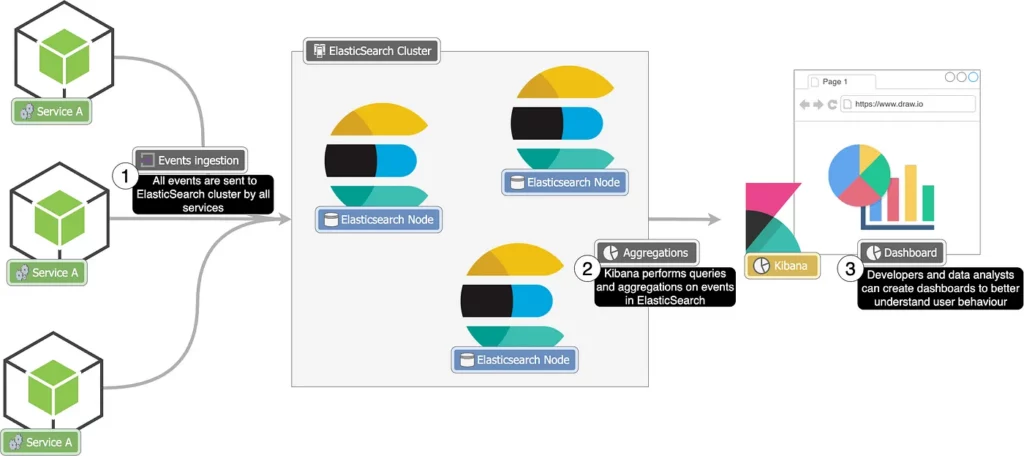
Come sistema di raccomandazioni
In ElasticSearch è possibile costruire query che diano maggiore preferenza a determinati attributi. Memorizzando alcune informazioni sull’utente, come il paese, l’età, le preferenze e così via, potremmo generare query per ottenere film o serie popolari per quell’utente andando a pesare maggiormente alcuni campi.
Conclusione
Come progettare cluster ElasticSearch?
L’architettura di un cluster ElasticSearch non è un’impresa facile: richiede la conoscenza di nodi, shard, indici e di come orchestrarli tutti. Le scelte architettoniche da fare sono pressoché infinite e il campo è in continua evoluzione (soprattutto con la popolarità dell’intelligenza artificiale e della ricerca alimentata dall’intelligenza artificiale). Esistono molti articoli e libri sull’argomento, oltre alla documentazione ufficiale di Elasticsearch.
Capire le query di ricerca e migliorare i sistemi di ricerca
La ricerca è complessa per definizione. Ci sono molti modi per migliorare i sistemi di ricerca, rendendoli più potenti e in grado di comprendere le esigenze degli utenti. Se volete imparare come interrogare Elasticsearch potete esplorare gli articoli che trovate qui.
Ricerca consapevole del contesto
In molti contesti, la ricerca non deve essere solamente testuale ma anche semantica. La ricerca semantica è un insieme di tecniche di ricerca che mira a comprendere il significato delle query degli utenti e il contesto dei contenuti, consentendo di ottenere risultati di ricerca più accurati e contestualmente rilevanti, considerando le relazioni tra le parole e l’intento alla base della ricerca. Pensate quando si va in libreria e si cerca un libro su un determinato argomento. Il negoziante valuterà attentamente la nostra richiesta valutando anche altri aspetti, come a cosa ci serve l’età del lettore, ecc. Questo aspetto è da considerare in fase di progettazione di sistemi avanzati.


