
NoSQL databases, including MongoDB, were created with the goal of overcoming some of the limitations of relational databases. The term “NoSQL” was used for the first time in 1998 by Carlo Strozzi during a meeting in San Francisco where he presented a database that could be queried via shell scripts. Since that initial idea, there have been many developments. However, a feature that unites the various types of databases is scalability, i.e. the ability to use clusters of servers to perform queries and update data efficiently.
MongoDB provides two main techniques to achieve both vertical and horizontal scalability: replica sets and sharding. In this article we’re going to cover the basic concepts of replica sets that are the basis of all MongoDB Atlas installations and any production application configuration. If you want to get a free account on MongoDB Atlas I suggest you to read the article MongoDB Atlas – creating a cloud environment for practice.
Definition
A replica set is a group of processes (also called instances) mongod that maintain the same set of data.
A replica set allows for data redundancy, thereby increasing fault tolerance and data availability. Fault tolerance is possible in that even if one member of the replica set is no longer functional or reachable, the other members continue to function providing the required service. In addition, when properly configured, a replica set can be used to distribute the load of reads across multiple servers. For example, some distributed applications may benefit from the replica set to direct read operations to the data center closest to the requesting client. Other purposes for which a replica set configuration is used include disaster recovery, periodic report generation, and database backup.
Members of a replica set
Before addressing the architecture of a replica set, it is necessary to introduce the various types of mongod instances that will constitute it.
Each mongod instance belonging to a replica set can belong to only one of the following categories.
Primary
The primary node receives all write operations. A replica set can only have one primary node that is responsible for confirming writes that have occurred on the other nodes. In order to perform data replication on all other nodes, each operation is written to the oplog. The number of nodes required to confirm that the data has been written is specified when configuring the replica set using write concern parameters. Typically, the basic configuration involves a write confirmation from the majority of nodes ({ w: “majority” }).
Secondary
A secondary node contains a copy of the primary’s data. Replication of the data is accomplished by the secondary node reading the primary’s oplog in an asynchronous process. Several secondary nodes may exist in a replica set. Applications, more specifically clients, cannot perform writes to a secondary member. However, it is possible to allow reading data stored on these nodes. To do this, you need to define read options for the replica set. By default, the reading takes place on the primary, but it is possible, for example, to indicate to read preferably from the secondary (secondaryPreferred option) or from the “nearest” node, i.e. the node with the lowest network latency. A secondary can become a primary (see automatic failover section).
Attention
Read queries on secondary nodes may not reflect the state of the data on the primary because data replication occurs asynchronously.
Using some special configurations it is possible to assign some secondary nodes to specific purposes.
For example, by setting the parameter {priority: 0}, a secondary node can never be elected primary. Usually this choice is made when the node does not reside in the main data center or to create a standby node (i.e. a node that can replace a node that is no longer available in case of emergency).
If you set the hidden param to true you create a secondary node that is invisible to the application. These nodes always have priority equal to 0 and, therefore, cannot become primary. However, they participate in the election of the primary. Their purpose is mainly to have nodes dedicated to data backup or reporting. In fact these instances receive only the traffic related to data replication and are consequently very unloaded compared to the other nodes in the replica set.
Finally, the slaveDelay parameter is used to create secondary nodes that keep a copy of the data deferred from the current one. The purpose is to have a temporal snapshot of the data in order to recover it in case of some errors, such as a failed software or model update.
Arbiter
These types of nodes are created when you do not have the physical ability to allocate another instance of mongod that contains a replica of the data. Referees are nodes that do not contain data and therefore cannot be elected primary. Despite this, I can participate in the election of the primary with a vote of 1. The idea of including a referee is to keep an odd number of votes during the election of the primary and avoid a tie.
Architecture of a replica set
Starting with the definitions of the various members, the simplest and also most widely used architecture consists of 3 mongod instances. MongoDB Atlas provides just this configuration already in its free installation (see article). Therefore, a primary will be chosen, while the other nodes will become secondary. Using the default configuration, applications will always operate on the primary, both in read and write. Secondary nodes will be involved only for data replication operations and replica set status monitoring.
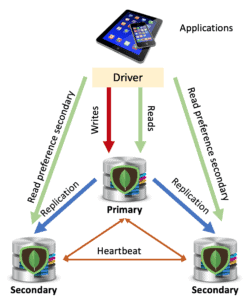
As we said before, if there are hardware restrictions for the creation and management of 3 copies of data, it is possible to use an arbiter. In this way you will always have an architecture based on 3 members, but only 2 of them will be used to save data.

Attention
A arbiter will always be an arbiter, whereas a primary may resign and become a secondary and a secondary may become the primary during an election.
Automatic Failover
Each node in a replica set sends a ping to the other members every 2 seconds. If the primary node does not communicate with the other members for longer than the configured period (TimeoutMillis parameter equal to 10 seconds by default), an eligible secondary, i.e., with priority equal to or greater than 1 requires an election. The goal is for the remaining members within the replica set to elect a new primary as soon as possible to resume normal operations.
During the period of the election of the new primary, the replica set cannot perform write operations. However, if you have properly configured reading from the secondaries as well, read queries can continue to work. In this way, not all services of the application would be suspended. You should consider that the optimal median time should not exceed 12 seconds. This estimate assumes the use of standard configurations and low network latency. It also includes the time it takes to mark the current primary as unavailable and complete the election.
Since not all architectures are the same, it is possible to set the time after which a primary is labeled as unavailable. The parameter is
settings.electionTimeoutMillis set to 10 seconds by default. Changing this setting should be done after an analysis of the election frequency and the lack of fault detection. Lowering the electionTimeoutMillis results in faster failure detection, but is more sensitive to network latencies and/or primary node overload. This leads to a high number of elections even if the primary is operational and to a lowering of the reliability of the application. Conversely, increasing the electionTimeoutMillis less sensitive to the above issues with the risk, however, of not detecting a failure on the primary in a reasonable time.
In order to integrate the management of automatic failovers within the applications it is necessary to use the MongoDB drivers. Since version 4.2 these allow to automatically retry write operations 1 time. Older drivers, those compatible with versions 4.0 and 3.6, require this behavior to be specified using the retryWrites=true option within the connection string.
One of the new features of version 4.4 is mirror reading. This option, enabled by default, allows reads from the cache of an eligible secondary (priority greater than or equal to 1) improving the performance of the replica set during the election of the primary.
Transactions
One of the great innovations included in MongoDB in the latest versions is the ability to create multi-document transactions. We must remember that until version 4.0, the atomicity of data writing operations (insert, delete, update) were guaranteed only at the level of a single document. With the advent of transactions MongoDB has overcome this problem, thus increasing the possibility of using this NoSQL database in different application contexts.
Attention
Transactions are only available on replica set configurations. Since version 4.2 it is also possible to use them on sharded clusters. However, there are some limitations, including the inability to write to capped and system.* collections, and to access config, admin and local collections. For more details see the official documentation.
All queries defined within a transaction must be directed to the primary. Therefore, if there are any read operations inside the transaction you must set read preferences on the primary.
Changes made to documents involved in the transaction will not be visible outside the transaction until the transaction is committed.
According to the official documentation, however, there is the special case of writing to multiple shards. In this context, some reads (those with the local read preference) may read a portion of the modified data that is not consistent with the entire replica set. Care must therefore be taken when using read preferences in order to avoid “ghost reads”.
Additional features
There are several replica set options that can be used to improve application performance, distribute the workload across distributed data centers or create as we mentioned nodes dedicated to reporting, disaster recovery and time-based backup snapshots.
For example, mirror reads, enabled by default, allow you to distribute a percentage of the required reads on secondary nodes. This decreases the workload on the primary node without compromising the operation of the application.
Another feature of replica sets and shards is the ability to access change streams. Change streams record data changes in real time without the complexity of an oplog. Since they are based on the aggregation framework, it’s possible to set them on specific change events of interest for the application. More details can be found in the official documentation.
Finally, a widely used feature is the ability to manipulate the election of the primary via the priority of each node (members[n].priority). As we will see in the next article, by setting the priority of a given node higher than the other members we can determine a priori which will be the primary. This technique is used to define a hierarchy among the various members of the replica set in order to elect the primary node that resides in the data center with the best performance.


