
I database NoSQL, tra cui MongoDB, sono nati con l’obiettivo di superare alcune limitazioni dei database relazionali. Il termine “NoSQL” fu utilizzato per la prima volta nel 1998 da Carlo Strozzi durante un meeting a San Francisco in cui presentò un database che poteva essere interrogato tramite script shell. Da quell’idea iniziale gli sviluppi sono stati molteplici. Una caratteristica che però accomuna le varie tipologie di database è la scalabilità, ossia la possibilità di utilizzare cluster di server per effettuare le interrogazioni e l’aggiornamento dei dati in modo efficiente.
MongoDB fornisce due tecniche principali per ottenere una scalabilità sia verticale che orizzontale: i replica set e lo sharding. In questo articolo andremo a trattare i concetti base dei replica set che sono alla base di tutte le installazioni di MongoDB Atlas e di qualsiasi configurazione per applicazioni di produzione. Se volete ottenere un account gratis su MongoDB Atlas vi suggerisco di leggere l’articolo MongoDB Atlas – creazione di un ambiente cloud per esercitarsi.
Definizione
Un replica set è un gruppo di processi (dette anche istanze) mongod che mantengono lo stesso insieme di dati.
Un replica set permette la ridondanza dei dati aumentando, di conseguenza, la tolleranza ai guasti e la disponibilità dei dati. La tolleranza ai guasti è possibile in quanto anche se un membro del replica set non è più funzionante o raggiungibile, gli altri membri continuano a funzionare fornendo il servizio richiesto. Inoltre, se opportunamente configurato, un replica set può essere utilizzato per distribuire il carico delle letture su diversi server. Ad esempio, alcune applicazioni distribuite possono beneficiare del replica set per indirizzare le operazioni di lettura al data center più vicino al client richiedente. Altri scopi per cui è utilizzata una configurazione di un replica set sono il disaster recovery, la generazione di report periodici e il backup dei database.
I membri di un replica set
Prima di affrontare l’architettura di un replica set è necessario introdurre le varie tipologie di istanze mongod che lo costituiranno.
Ogni istanze mongod appartenente a un replica set può appartenere ad una sola delle seguenti categorie.
Primario
Il nodo primario riceve tutte le operazioni di scrittura. Un replica set può avere solo un nodo primario che è responsabile di confermare le scritture avvenute sugli altri nodi. Per poter effettuare la replica dei dati su tutti gli altri nodi, ciascuna operazione viene scritta nel oplog. Il numero di nodi necessari per confermare l’avvenuta scrittura dei dati viene specificato in fase di configurazione del replica set mediante i parametri di write concern. Di solito, la configurazione base implica una conferma di scrittura dalla maggioranza dei nodi ({ w: “majority” }).
Secondario
Un nodo secondario contiene una copia dei dati del primario. La replicazione dei dati avviene mediante la lettura da parte del nodo secondario dell’oplog del primario con un processo asincrono. In un replica set possono esistere diversi nodi secondari. Le applicazioni, più precisamente i client, non possono effettuare scritture su un membro secondario. Tuttavia è possibile permettere la lettura dei dati salvati in questi nodi. Per fa ciò è necessario definire le opzioni di lettura del replica set. Di default la lettura avviene sul primario, ma è possibile ad esempio indicare di leggere preferibilmente dal secondario (opzione secondaryPreferred) oppure dal nodo più “vicino” (nearest) ossia il nodo con minor latenza di rete. Un secondario può diventare un primario (vedi la sezione riguardo al failover automatico).
Attenzione
Le query di lettura sui nodi secondari potrebbero non riflettere lo stato dei dati sul primario in quanto la replicazione dei dati avviene in modo asincrono.
Utilizzando alcune configurazioni particolari è possibile adibire alcuni nodi secondari a scopi specifici.
Ad esempio settando il parametro {priority: 0}, un nodo secondario non potrà essere mai eletto primario. Di solito questa scelta viene fatta quando il nodo non risiede nel data center principale oppure per creare un nodo di standby (ossia un nodo che possa sostituire un nodo non più disponibile in caso di emergenza).
Se invece si imposta il param hidden a true si crea un nodo secondario che è invisibile all’applicazione. Questi nodi hanno sempre priorità uguale a 0 e, quindi, non possono diventare primari. Nonostante ciò partecipano durante l’elezione del primario. Il loro scopo è principalmente di avere dei nodi dedicati al backup dei dati o alla creazione della reportistica. Infatti queste istanze ricevono solo il traffico relativo alla replicazione dei dati e risultano di conseguenza molto scarichi rispetto agli altri nodi del replica set.
Infine, il parametro slaveDelay viene utilizzato per creare dei nodi secondari che mantengono una copia dei dati differiti rispetto a quella attuale. Lo scopo è di avere uno snapshot temporale dei dati per recuperarlo nel caso di alcuni errori, come ad esempio un aggiornamento software o di modello fallito.
Arbitro
Questa tipologia di nodi vengono creati quando non si ha la possibilità fisica di allocare un altra istanza di mongod che contenga una replica dei dati. Gli arbitri, infatti, sono nodi che non contengono dati e che perciò non possono essere eletti primari. Nonostante ciò, posso partecipare all’elezione del primario con voto pari a 1. L’idea di inserire un arbitro è per mantenere un numero di voti dispari durante l’elezione del primario evitando un pareggio.
Architettura di un replica set
Partendo dalle definizione dei vari membri, l’architettura più semplice e anche maggiormente utilizzate è costituita da 3 istanze mongod. MongoDB Atlas fornisce proprio questa configurazione già nella sua installazione gratuita (vedi articolo). Verrà pertanto scelto un primario, mentre gli altri nodi diventeranno secondari. Utilizzando la configurazione di default, le applicazioni opereranno sempre sul primario, sia in lettura che in scrittura. I nodi secondari saranno coinvolti solo per le operazioni di replicazione dei dati e di monitoraggio dello stato del replica set.
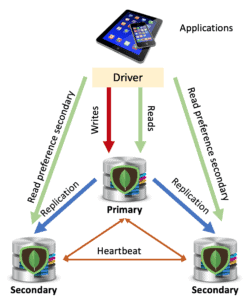
Come abbiamo detto in precedenza, se ci fossero restrizioni di tipo hardware per la creazione e gestione di 3 copie dei dati, è possibile utilizzare un arbitro. In questo modo si avrà sempre un’architettura basata su 3 membri, di cui solo 2 però saranno adibiti al salvataggio dei dati.

Attenzione
Un arbitro sarà sempre un arbitro, mentre un primario può dimettersi e diventare un secondario e un secondario può diventare il primario durante un'elezione.
Failover automatico
Ogni nodo di un replica set inviano ogni 2 secondi un ping agli altri membri. Se il nodo primario non comunica con gli altri membri per un periodo superiore a quello configurato (parametro TimeoutMillis pari a 10 secondi di default), un secondario eleggibile, ossia con priorità pari o superiore a 1 richiede un’elezione. L’obiettivo è che i membri rimasti all’interno del replica set eleggano un nuovo primario nel minor tempo possibile per riprendere le normali operazioni.
Durante il periodo dell’elezione del nuovo primario, il replica set non può effettuare operazioni scrittura. Tuttavia, nel caso si fosse opportunamente configurata la lettura anche dai secondari, le interrogazioni in lettura possono continuare a funzionare. In questo modo non tutti servizi dell’applicazione verrebbero sospesi. Bisogna considerare che il tempo mediano ottimale non dovrebbe superare i 12 secondi. Questa stima presuppone l’utilizzo delle configurazioni standard e una latenza di rete bassa. Inoltre include il tempo necessario per contrassegnare il primario attuale come non disponibile e completare l’elezione.
Poiché non tutte le architetture sono uguali è possibile impostare il tempo dopo il quale un primario viene etichettato come irraggiungibile. Il parametro è
settings.electionTimeoutMillis che di default è pari a 10 secondi. La modifica di questa impostazione deve avvenire a seguito di un’analisi della frequenza di elezioni e della mancanza di individuazione di guasti. Abbassando l’electionTimeoutMillis si è più veloci nell’individuazione di un guasto, ma si è più sensibili alle latenze di rete e/o a un sovraccarico del nodo primario. Ciò comporta un numero elevato di elezioni anche qualora il primario sia operativo e ad un abbassamento dell’affidabilità dell’applicazione. Diversamente, aumentando l’electionTimeoutMillis si è meno sensibili alle problematiche precedenti con il rischio però di non individuare in tempi ragionevoli un guasto sul primario.
Per integrare la gestione dei failover automatici all’interno delle applicazioni è necessario utilizzare i driver di MongoDB. Dalla versione 4.2 questi consentono di riprovare automaticamente le operazioni di scrittura 1 volta. I driver più vecchi, quelli compatibili con le versioni 4.0 e 3.6, richiedono che questo comportamento sia specificato mediante l’opzione retryWrites=true all’interno della stringa di connessione.
Una delle novità della versione 4.4 è la lettura mirror. Questa opzione, abilitata di default, permette di effettuare le letture dalla cache di un secondario eleggibile (priority maggior o uguale a 1) migliorando le performance del replica set durante l’elezione del primario.
Transazioni
Una delle grandi novità inserite in MongoDB nelle ultime versioni è la possibilità di creare transazioni multi-documento. Bisogna ricordare che fino alla versione 4.0, l’atomicità delle operazioni di scrittura dei dati (insert, delete, update) erano garantite solo a livello di singolo documento. Con l’avvento delle transazioni MongoDB ha ovviato a questo problema aumentando di conseguenza la possibilità di utilizzo di questo database NoSQL in diversi contesti applicativi.
Attenzione
Le transazioni sono disponibili solo su configurazioni in replica set. Dalla versione 4.2 è possibile utilizzarle anche su sharded clusters. Tuttavia ci sono alcune limitazioni tra cui l'impossibilità di scrivere in collezioni capped e system.*, ed accedere alle collezioni config, admin e local. Per maggiori dettagli vi rimandiamo alla documentazione ufficiale.
Tutte le query definite all’interno di una transazione devono essere indirizzate al primario. Pertanto, se al suo interno ci sono operazioni di lettura bisogna impostare le preferenze di lettura sul primario.
Le modifiche effettuate sui documenti coinvolti dalla transazioni non saranno visibili all’esterno della transazione finché non verrà effettuato il commit.
Secondo la documentazione ufficiale, esiste però il caso particolare di scrittura su più shard. In questo contesto, alcune letture (quelle con la preferenza di lettura locale) potrebbero leggere una porzione dei dati modificati non coerente con l’intero replica set. Bisogna quindi fare attenzione quando si usano le preferenze di lettura al fine di evitare “letture fantasma”.
Ulteriori caratteristiche
Esistono diverse opzioni dei replica set che possono essere utilizzate per migliorare le performance delle applicazioni, distribuire il carico di lavoro su data center distribuiti o creare come abbiamo accennato nodi dedicati alla reportistica, disaster recovery e snapshot di backup temporali.
Ad esempio, le letture mirror, abilitate di default, permettono di distribuire una percentuale delle letture richieste sui nodi secondari. In questo modo si diminuisce il carico di lavoro del nodo primario senza compromettere il funzionamento dell’applicazione.
Un’altra caratteristica dei replica set e degli shard è la possibilità di accedere ai change streams. I change streams registrano i cambiamenti dei dati in tempo reale senza però la complessità dell’oplog. Essendo basati sull’aggregation framework è possibile impostarli su specifici eventi di modifica di interesse per l’applicazione. Ulteriori dettagli li trovate nella documentazione ufficiale.
Infine, una caratteristica molto utilizzata è la possibilità di manipolare l’elezione del primario mediante la priorità di ciascun nodo (members[n].priority). Come vedremo nel prossimo articolo, impostando la priorità di un determinato nodo più alta rispetto agli altri membri possiamo determinare a priori quale sarà il primario. Questa tecnica viene usata per definire una gerarchia tra i vari membri del replica set l fine di far eleggere il nodo primario che risiede nel data center con le migliori prestazioni.


