
Relational databases are a well-established technology applied in various fields since the late 1980s. The characteristics that have made the fortune of this technology are: the simplicity of the model and the support for transactions. The relational model can be summarized as a set of tables connected by the values of certain fields. Each table contains a set of nonredundant information. These features ensure greater data consistency provided the model has been well designed. The transactional system, i.e., the support of transaction management, makes it possible, in parallel, to verify that a set of operations (reads and writes) to the database are all being performed correctly. If this does not happen a rollback is done, i.e., undoing everything in order to return the database to its initial state before the transaction begins. However, there are some scenarios in which relational databases are not really suitable. Suppose we want to represent a hierarchy with an undefined depth a priori. In this case it is necessary to use recursive relationships. These relationships imply that a table will have a foreign key that references the table’s primary key. Writing data within them is simple and does not differ from normal writing. However, efficiently querying a recursive relation is not so straightforward.
In this article we will introduce recursive queries in the SQL language in order to navigate a hierarchy efficiently. Before we look at the syntax used, we will illustrate the alternative technologies available to implement a tree or graph. Let’s get started.
Alternatives to recursive queries: NoSQL databases
As seen above, relational databases are widely used despite having some limitations. In addition to the difficulty of querying a hierarchy, for example, there are limitations on handling data types that are very heterogeneous in terms of the same characteristics. In addition, the efficiency of queries depends greatly on how many tables are involved and their size.
These reasons, together with other needs of database developers and designers, led to the emergence of NoSQL databases. The models used are diverse and have their origins in models presented many years earlier (in the second half of the 1900s). For example, the document model is the basis of MongoDB, Elastisearch and many other databases. Otherwise, the key-value model, together with the use of main memory only, is the secret of Redis‘ success. Finally, Neo4j is the database that exploits the full potential of a graph model and graph theory algorithms.
The best models to represent our case study, i.e., a hierarchy, are:
- Document model
- Graph model
The first, whose prominent representative is MongoDB, is based on a representation of information using json documents. This allows information with very heterogeneous structures and data types to be saved. However, representing a hierarchy is not so straightforward. It is possible, for example, to use a vector of documents sorted by some criteria. This solution implies that information is replicated in several documents, and the document itself may become too large to be retrieved efficiently. Graphs, on the other hand, could not be represented in any way by this solution. However, there is a modeling pattern, called a tree or graph, that succeeds in overcoming these limitations. If you want to learn more, you can read the book Design with MongoDB: Best models for applications.
Once the documents have been modeled appropriately, queries will be made in MongoDB using aggregation pipelines. In particular, you will use the $graphLookup stage to navigate through the documents. Its execution takes some resources and may not finish if the amount of data is too large.
The second model finds its best implementation in Neo4j. This database represents data just like a graph. Queries, written in the CYPHER language, are geared both to filter nodes of interest, but more importantly to navigate from node to node based on the semantics of the arcs, the types of nodes, and their characteristics. Neo4j is definitely the best choice for scenarios where queries are oriented toward discovering even very deep relationships between data. However, in other contexts such as managing financial transactions in time or collecting time series are not the best choice.
Recursive Queries in SQL
Initially in the SQL language it was not possible to efficiently navigate hierarchies. Suppose we have the following schema.
EMPLOYEES (CodI, FirstName, LastName, BossID*).
Let me remind you that the notation used to describe the schema uses underscores to indicate the fields that make up the primary key and asterisks to indicate the possibility of assigning NULL values to the field. In this case, the BossID field is a foreign key that points to the CodI field in the same table.
To discover the chain of command from a single employee it was necessary to know its depth and perform joins with various instances of the same table. A possible solution, with a hierarchy depth of 3, was as follows:
SELECT *
FROM EMPLOYEES I1, EMPLOYEES I2, EMPLOYEES I3
WHERE I1.BossID=I2.CodI AND I2.BossID=I3.CodI
AND I1.CodI = 1;
This query not only potentially provides a result but is also inefficient. In fact, if the table employed contains many records, the query execution time may be very long or even fail to terminate due to reaching resource limits.
To overcome this problem, recursive CTEs were introduced. The syntax is very similar to what we saw for CTEs in the article SQL: Common Table Expression. However, they require both the recursive command and the use of the UNION ALL set operator (see SELECT: set operators). The structure of a recursive CTE is as follows.
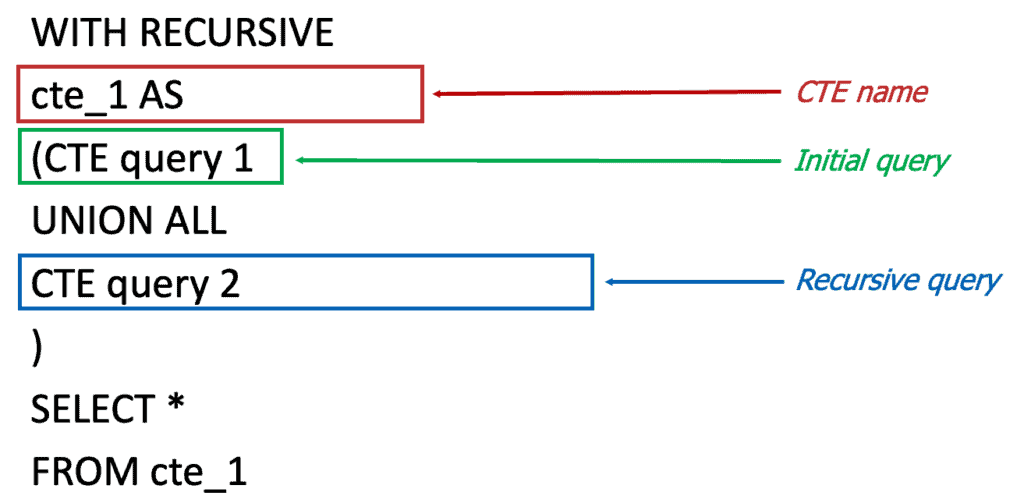
Returning to our example of a company’s organizational chart, the SQL query will result in the following:
WITH RECURSIVE hierarchy AS (
SELECT CodI, FirstName, LastName, BossID, 0 AS level
FROM EMPLOYEES
WHERE BossID IS NULL
UNION ALL
SELECT I.CodI, I.FirstName, I.LastName, I.BossID, level +1
FROM EMPLOYEES I, hierarchy G
WHERE I.BossID = G.CodI
)
SELECT G.FirstName, G.LastName, I.FirstName AS FirstNameBoss, I.LastName AS LastNameBoss, level
FROM hierarchy G LEFT JOIN EMPLOYEES I ON G.BossID= I.CodI
ORDER BY level;
The initial query selects all records for which there is no superior for that employee. It starts, therefore, with the bosses of the entire organization. The recursive query, on the other hand uses the same CTE to identify employees who are directly under the bosses. At subsequent iterations, the bosses will change and consequently so will the employees selected by the second query. Thus, the hierarchy is navigated using a top-down approach. At each iteration a level field is added in order to indicate the level of recursion reached. The results of the two queries are connected using the UNION ALL ensemble operator. To conclude, the hierarchical CTE is joined with a LEFT OUTER JOIN to the table EMPLOYED in the main query to show all the results obtained and sorted by the calculated level.
Recursive CTEs solve the problem of navigating a hierarchy in relational databases. However, their execution can be cumbersome and limited to the depth analyzed by the RDBMS used.


