
I database relazionali sono una tecnologia ben consolidata applicata in diversi settori fin dalla fine degli anni 80 del secolo scorso. Le caratteristiche che hanno fatto la fortuna di questa tecnologia sono: la semplicità del modello e il supporto alle transazioni. Il modello relazionale si può riassumere come un insieme di tabelle connesse tra loro mediante i valori di alcuni campi. Ogni tabella contiene un insieme di informazioni non ridondanti. Queste caratteristiche assicurano una maggior consistenza dei dati a patto che il modello sia stato ben progettato. Il sistema transazionale, ossia il supporto della gestione delle transazioni, permette, parallelamente, di verificare che una serie di operazioni (letture e scritture) sul database vengano tutte eseguite correttamente. Se ciò non accade viene fatto il rollback, ossia l’annullamento di tutto al fine di riportare il database allo stato iniziale prima dell’inizio della transazione. Tuttavia, esistono alcuni scenari in cui i database relazionali non sono propriamente adatti. Supponiamo di voler rappresentare una gerarchia con una profondità non definita a priori. In questo caso è necessario usare delle relazioni ricorsive. Queste relazioni implicano che una tabella avrà una chiave esterna che si referenzia alla chiave primaria della tabella stessa. Scrivere i dati al loro interno è semplice e non differisce da una scrittura normale. Tuttavia, interrogare in modo efficiente una relazione ricorsiva non è così immediato.
In questo articolo introdurremo le query ricorsive nel linguaggio SQL al fine di navigare una gerarchia in modo efficiente. Prima di vedere la sintassi usata, illustreremo le tecnologie alternative disponibili per implementare un albero o un grafo. Iniziamo!
Alternative alle query ricorsive: i database NoSQL
Come visto in precedenza, i database relazionali sono largamente usati nonostante presentino alcune limitazioni. Oltre alla difficoltà di interrogare una gerarchia, ad esempio, si hanno limitazioni sulla gestione di tipologie di dati molto eterogenei per le stesse caratteristiche. Inoltre, l’efficienza delle query dipende molto da quante tabelle sono coinvolte e dalle loro dimensioni.
Questi motivi, insieme ad altre necessità degli sviluppatori e progettisti dei database, hanno portato alla nascita dei database NoSQL. I modelli usati sono diversi e affondano le loro origini su modelli presentati molti anni prima (nella seconda metà del 900). Ad esempio, il modello documentale è alla base dei database MongoDB, Elastisearch e molti altri. Diversamente il modello chiave valore, insieme all’impiego della sola memoria principale, è il segreto del successo di Redis. Infine, Neo4j è il database che sfrutta tutte le potenzialità di un modello a grafo e degli algoritmi della teoria dei grafi.
I migliori modelli per rappresentare il nostro caso di studio, ossia una gerarchia, sono:
- Modello documentale
- Modello a grafo
Il primo, il cui rappresentate di spicco è MongoDB, si base su una rappresentazione dele informazioni mediante documenti json. Ciò permette di salvare informazioni con strutture e tipologie di dato molto eterogenee. Tuttavia, rappresentare una gerarchia non è così immediato. È possibile, ad esempio, usare un vettore di documenti ordinato con qualche criterio. Questa soluzione implica che le informazioni sono replicate in diversi documenti e il documento stesso potrebbe diventare troppo grande per essere recuperato in modo efficiente. I grafi, invece, non potrebbero essere rappresentati in nessuna maniera mediante questa soluzione. Esiste però un pattern di modellazione, chiamato ad albero o grafo, che riesce a superare questi limiti. Se volete approfondire potete leggere il libro Progettare con MongoDB: I migliori modelli per le applicazioni.
Una volta modellati opportunamente i documenti, le interrogazioni verranno effettuate in MongoDB con le pipeline di aggregazione. In particolare, si userà lo stage $graphLookup per navigare tra i documenti. La sua esecuzione richiede un po’ di risorse e potrebbe non terminare se la quantità di dati è troppo grande.
Il secondo modello trova la sua migliore implementazione in Neo4j. Questo database rappresenta i dati proprio come un grafo. Le query, scritte nel linguaggio CYPHER, sono orientate sia a filtrare i nodi di interesse, ma soprattutto a navigare da un nodo all’altro in base alla semantica degli archi, le tipologie di nodi e le loro caratteristiche. Neo4j è sicuramente la scelta migliore per scenari in cui le interrogazioni sono orientate a scoprire relazioni tra i dati anche molto profonde. Tuttavia, in altri contesti come la gestione in tempo di transazioni finanziare o la raccolta di serie temporali non sono la scelta migliore.
Query ricorsive in SQL
Inizialmente nel linguaggio SQL non era possibile navigare in modo efficiente delle gerarchie. Supponiamo di avere il seguente schema
IMPIEGATI (CodI, Nome, Cognome, BossID*)
Vi ricordo che la notazione usata per descrivere lo schema usa la sottolineatura per indicare i campi che compongono la chiave primaria e l’asterisco per segnalare la possibilità di assegnare valori NULL al campo. In questo caso il campo BossID è una chiave esterna che punta al campo CodI della stessa tabella.
Per scoprire la catena di comando partendo da un singolo impiegato era necessario conoscere la sua profondità ed effettuare delle join con varie istanze della stessa tabella. Una soluzione possibile, con una profondità della gerarchia pari a 3, era la seguente:
SELECT *
FROM IMPIEGATI I1, IMPIEGATI I2, IMPIEGATI I3
WHERE I1.BossID=I2.CodI AND I2.BossID=I3.CodI
AND I1.CodI = 1;
Questa query non solo fornisce un risultato potenzialmente ma è anche inefficiente. Infatti, se la tabella impiegato contiene molti record il tempo di esecuzione della query potrebbe essere molto lungo o addirittura non terminare per raggiunti limiti di risorse.
Per ovviare a questo problema sono state introdotte le CTE ricorsive. La sintassi è molto simile a quella che abbiamo visto per le CTE nell’articolo SQL: CTE. Tuttavia, richiedono sia il comando recursive che l’utilizzo dell’operatore insiemistico UNION ALL (vedere SELECT: operatori insiemistici). La struttura di una CTE ricorsiva è la seguente
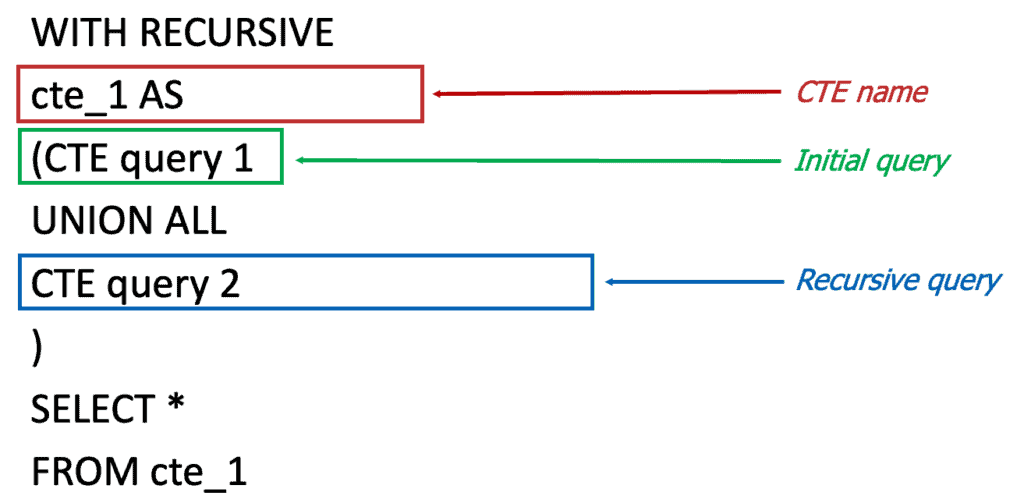
Tornando al nostro esempio dell’organigramma di un’azienda la query SQL risulterà la seguente:
WITH RECURSIVE gerarchia AS (
SELECT CodI, Nome, Cognome, BossID, 0 AS livello
FROM IMPIEGATI
WHERE BossID IS NULL
UNION ALL
SELECT I.CodI, I.Nome, I.Cognome, I.BossID, livello +1
FROM IMPIEGATI I, gerarchia G
WHERE I.BossID = G.CodI
)
SELECT G.Nome, G.Cognome, I.Nome AS NomeBoss, I.Cognome AS CognomeBoss, livello
FROM gerarchia G LEFT JOIN IMPIEGATI I ON G.BossID= I.CodI
ORDER BY livello;
La query iniziale seleziona tutti i record per cui non esiste un superiore per quell’impiegato. Si parte, pertanto, dai capi di tutta l’organizzazione. La query ricorsiva, invece usa la stessa CTE per identificare gli impiegati che sono direttamente sotto i capi. Alle iterazioni successivi i capi cambieranno e di conseguenza anche gli impiegati selezionati dalla seconda query. Si naviga, quindi, la gerarchia con un approccio top-down. Ad ogni iterazione un campo livello è aggiunto al fine di indicare il livello della ricorsione raggiunto. I risultati delle due query sono connessi mediante l’operatore insiemistico UNION ALL. Per concludere, la CTE gerarchia è unita con un LEFT OUTER JOIN alla tabella IMPIEGATI nella query principale per mostrare tutti i risultati ottenuti ed ordinata in base al livello calcolato.
Le CTE ricorsive risolvono il problema della navigazione di una gerarchia nei database relazionali. Tuttavia, la loro esecuzione può essere onerosa e limitata alla profondità analizzata dal RDBMS utilizzato.


