
In the previous article XXX, we began to analyze the structure of the SELECT statement in its main parts in order to write very simple queries to extract the information of interest and compute aggregate functions. The potentials of the SQL language, however, are much greater than those described. We will see, therefore, how it is possible to join the contents of one or more tables and group the data into subsets.
Also in this article we will use the schema from last time related to movie showings in cinemas.
MOVIE (CodM, Title, Release_Date, Genre, DurationMinutes)
CINEMA (CodC, Name, Address, City, Website*)
ROOM (CodC, RoomNumber, Capacity)
PROJECTION (CodC, RoomNumber, Date, StartTime, EndTime, CodM)
As a reminder, the notation used to describe the schema uses underscores to indicate the fields that make up the primary key and asterisks to indicate the possibility of assigning NULL values to the field. Finally, for simplicity, foreign keys have the same name as the primary keys to which they refer. At this point we are ready to address other aspects of the SELECT statement.
JOIN
The relational model by its definition requires that information be divided into different tables in order to avoid data redundancy. Using the Entity-Relationship model results in logical models adhering to this concept. If you want to delve into the whole design phase I recommend my book available here. Therefore, when we need to retrieve information we have many times the need to merge the contents of several tables into one result.
In our example we might be interested in displaying the movie title of each screening on a particular day. To do this, the PROJECTION table is not sufficient since it does not contain the details of the movie screened but only the foreign key. We need to merge them! The joining, however, should not be done randomly, but according to the value of the CodF field. So, for each record in the PROJECTION table we need to “hook” the row in the FILM table that has the same value for the CodM field. But how can we indicate in the SQL statement to do this join?
Basically, we can formalize the join using FROM and WHERE clauses where we respectively indicate the tables involved and then the tuple join conditions.
The result and efficiency of the query are independent of both the order of the tables in the FROM clause and the order of the predicates in the WHERE clause. In fact, it is the job of the optimizer (DBMS module) to identify the execution plan, i.e., the data access methods and sequence of operations, that is optimal for making the query efficient. Using this syntax, one rule that follows is that if N tables are inserted in the FROM clause, it will be necessary to insert at least N-1 join conditions in the WHERE clause.
Returning to our example, the query that allows us to display both the individual screening and the scheduled movie information is as follows:
SELECT P.*, Title, Genre, DurationMinutes
FROM PROJECTION P, MOVIE M
WHERE P.CodM=M.CodM
AND Date = ‘2023-06-02’;
As you can see, I have assigned aliases to the tables (even without the keyword AS). This allows me to indicate which table the individual field belongs to by dot notation but without rewriting the entire table name. This writing strategy is useful in several ways. I reduce the time of writing the query itself in this way and also avoid typos. In return, if I need multiple instances of the same table, it is sufficient to assign two different aliases. Dot notation can be used all the time, but it is required compulsorily only to distinguish the reference table if the fields of two tables have the same name.
Alternative syntax
The syntax just presented is the simplest possible syntax. However, it has a flaw! Only if the join condition (whether equality or inequality does not matter) is met, then related records will appear in the result.
Let’s understand this better from an example! Suppose our schema allows NULL values in the CodM field of the projection table. Using the syntax seen above, the join condition defined in the WHERE will not be satisfied for all rows that have NULL value for that field. In fact, there is, by definition, no NULL key in the MOVIE table. So how do we also display the theaters that have not yet been associated with a movie to be shown?
We have to use an alternative syntax, which is more flexible but also a bit more verbose. The general syntax is as follows:
SELECT [DISTINCT] Attributes
FROM Table JoinType JOIN Table ON JoinCondition
[WHERE TupleConditions];
where the join types can be INNER or [FULL | LEFT | RIGHT] OUTER. You can see the differences between the various possible combinations in the image below.
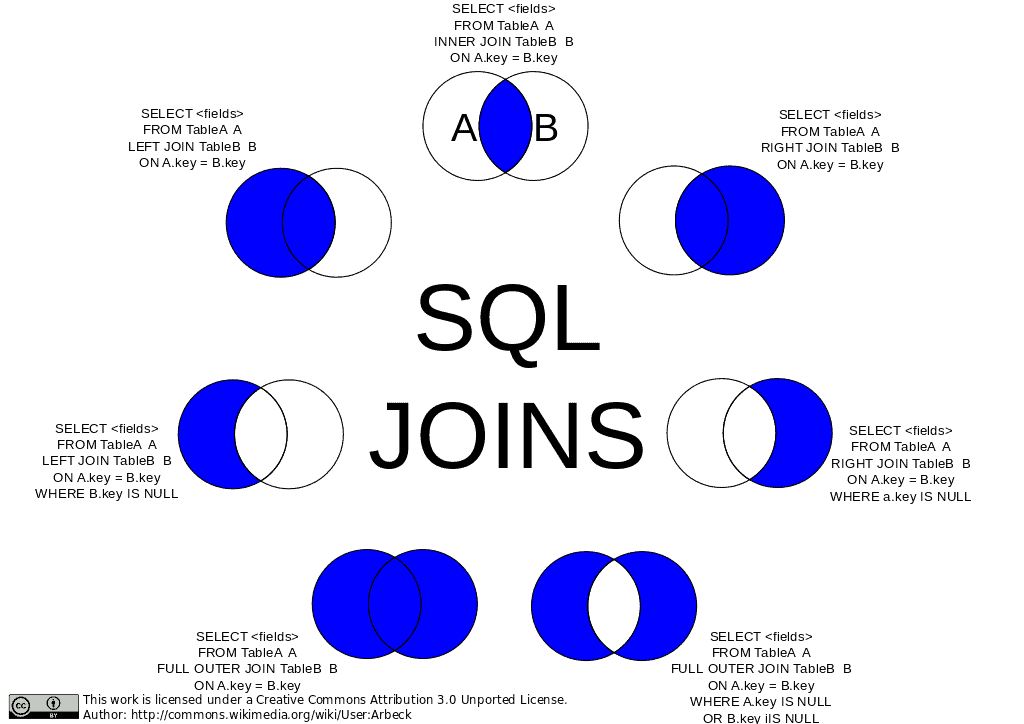
GROUP BY
If you have followed this and previous articles up to this point, you are now able to filter data with simple predicates and put together content that comes from different tables. We are missing a key piece in many scenarios: creating groups within our data. To do this, you need to use the GROUP BY clause. Its syntax is really simple:
GROUP BY ListAttributesOfGroup
The order of the grouping attributes is irrelevant, but their presence implies what can be included in the SELECT clause. In fact, only attributes defined in the GROUP BY clause can appear in the SELECT clause. So how do we display other information? To display other fields, simply include them in the GROUP BY clause. If these fields are uniquely determined by attributes already in the GROUP BY clause, they will not alter the definition of the groups.
But then what are groups for if not to eliminate duplicate values that could also be done with the keyword DISTINCT in the SELECT? The defined groups are used to compute aggregate functions on all the other attributes that were not included in the GROUP BY clause. We can thus know how many elements are in each group, calculate the average, the minimum and/or maximum value of a field, and even find the total of a field.
Let us therefore see an example! Suppose we want to calculate the number of screenings, the number of different theaters, and the number of different theaters for each movie. The query will be as follows:
SELECT Title, COUNT(*) AS NumProjections,
COUNT (DISTINCT CodC) AS NumCinemas
COUNT(DISTINCT CodC, RoomNumber) AS NumRooms
FROM PROJECTION P, MOVIE M
WHERE P.CodM=M.CodM
GROUP BY M.CodM, Title;
As you can see, in the GROUP BY clause both the movie code and the title were entered, but in the SELECT only the title. Why? The answer is related to the possibility of two movies having the same title (e.g. remakes). To avoid mistakenly grouping two movies based only on the title, we included the code, which is unique. At this point all the information (fields) of the movie can be added without altering the result.
Another observation to make are about the different uses of the COUNT function. In the first case we used COUNT(*) since we needed to count the number of elements in each group that corresponded to screenings of a movie. In the other two cases we used the keyword DISTINCT to count movie theaters and the number of theaters, respectively. The appropriate use of field combinations allows us to calculate different things! Therefore, the meaning of the result of the COUNT function depends on the context and the parameters passed.
HAVING
Defining groups is very useful for extracting certain statistics. In many cases, however, we are not interested in all groups but only those with certain characteristics. Can they therefore be filtered? Yes by means of the HAVING clause. The syntax is really simple.
HAVING GroupConditions
Group conditions can only be aggregate functions. Therefore, never think of inserting group conditions or aggregate functions in the WHERE clause, as the latter only accepts predicates referring to the single record.
Therefore, let us see an example of the application of the HAVING clause. We now want to display the information (name and address) of cinemas in Rome that have a total capacity among all the theaters available to them of less than 200 seats. The query will be as follows:
SELECT Name, Address
FROM CINEMA C, ROOM R
WHERE C.CodC=R.CodC
AND City=’Rome’
GROUP BY CodC, Name, Address
HAVING SUM(Capacity) < 200;
Again, in the GROUP BY clause we used the cinema key to define the groups and added the other fields (Name and Address) that we needed in the SELECT clause. The group condition with respect to overall capacity is, however, checked by means of the HAVING clause and the SUM aggregation function applied to the Capacity field.



One Response