
Nell’articolo precedente XXX, abbiamo iniziato ad analizzare la struttura dell’istruzione SELECT nelle sue parti principali al fine di scrivere interrogazioni molto semplici per estrarre le informazioni di interesse e calcolare funzioni aggregate. Le potenzialità del linguaggio SQL però sono molto superiori a quelle descritte. Vedremo, pertanto, com’è possibile unire il contenuto di una o più tabelle e raggruppare i dati in sottoinsiemi.
Anche in questo articolo useremo lo schema dell’altra volta relativo alle proiezioni dei film nei cinema.
FILM (CodF, Titolo, Data_uscita, Genere, DurataMinuti)
CINEMA (CodC, Nome, Indirizzo, Città, SitoWeb*)
SALA (CodC, NumeroSala, Capienza)
PROIEZIONE (CodC, NumeroSala, Data, OraInizio, OraFine, CodF)
Vi ricordo che la notazione usata per descrivere lo schema usa la sottolineatura per indicare i campi che compongono la chiave primaria e l’asterisco per segnalare la possibilità di assegnare valori NULL al campo. Infine, per semplificare, le chiavi esterne hanno lo stesso nome delle chiavi primarie a cui si riferiscono. A questo punto siamo pronti per affrontare altri aspetti dell’istruzione SELECT.
JOIN
Il modello relazionale per sua definizione richiede che le informazioni sia divise in tabelle diverse al fine di evitare la ridondanza dei dati. Usando il modello Entità-Relazione si ottengono dei modelli logici aderente a questo concetto. Se volete approfondire tutta la fase di progettazione vi consiglio il mio libro disponibile qui. Pertanto, quando dobbiamo recuperare le informazioni abbiamo molte volte la necessità di unire il contenuto di diverse tabelle in unico risultato.
Nel nostro esempio potremmo essere interessati a visualizzare il titolo del film di ciascuna proiezione in un giorno particolare. Per far ciò non è sufficiente la tabella PROIEZIONE in quanto non contiene i dettagli del film proiettato ma solo la chiave esterna. Abbiamo bisogno di unirle! L’unione però non deve essere fatta casualmente, ma in base al valore del campo CodF. Quindi, per ciascun record della tabella PROIEZIONE dobbiamo “agganciare” la riga della tabella FILM che ha lo stesso valore per il campo CodF. Ma come possiamo indicare nell’istruzione SQL a fare questa unione?
Di base si può formalizzare il join mediante le clausole FROM e WHERE dove rispettivamente si indicano le tabelle coinvolte e poi le condizioni di unione delle tuple.
Il risultato e l’efficienza dell’interrogazione sono indipendenti sia dall’ordine delle tabelle nella clausola FROM, sia dall’ordine dei predicati nella clausola WHERE. Infatti, è compito dell’ottimizzatore (modulo del DBMS) identificare il piano di esecuzione, ossia le modalità di accesso ai dati e la sequenza di operazioni, ottimale per rendere efficiente la query. Usando questa sintassi una regola che ne deriva è che se nella clausola FROM vengono inserite N tabelle, sarà necessario inserire almeno N-1 condizioni di join nella clausola WHERE.
Tornando al nostro esempio, la query che ci permette di visualizzare sia la singola proiezione che le informazioni del film in programma è la seguente:
SELECT P.*, Titolo, Genere, DurataMinuti
FROM PROIEZIONE P, FILM F
WHERE P.CodF=F.CodF
AND Data = ‘2023-06-02’;
Come potete notare ho assegnato degli alias alle tabelle (anche senza la keyword AS). Ciò mi permette di indicare a quale tabella appartiene il singolo campo mediante la dot notation senza però riscrivere l’intero nome della tabella. Questa strategia di scrittura è utile sotto vari aspetti. Riduco in questo modo il tempo di scrittura della query stessa ed evito anche errori di battitura. In compenso, se ho necessità di più istanze della stessa tabella è sufficiente assegnare due alias diversi. La dot notation può essere usata sempre, ma è richiesta obbligatoriamente solo per distinguere la tabella di riferimento qualora i campi di due tabelle abbiamo lo stesso nome.
Sintassi alternativa
La sintassi appena presentata è quella più semplice possibile. Ha però un difetto! Solo se la condizione di join (che sia di uguaglianza o disuguaglianza non importa) viene soddisfatta, allora nel risultato compariranno i record correlati.
Capiamolo meglio da un esempio! Supponiamo che il nostro schema permette di inserire valori NULL nel campo CodF della tabella proiezione. Usando la sintassi vista precedentemente, la condizione di join definita nella WHERE non sarà soddisfatta per tutte le righe che hanno valore NULL per quel campo. Infatti, non esiste, per definizione, una chiave NULL nella tabella FILM. Quindi come facciamo a visualizzare anche le sale a cui non è stato ancora associato un film da proiettare?
Dobbiamo usare una sintassi alternativa, più flessibile ma anche un pò più verbosa. La sintassi generale è la seguente:
SELECT [DISTINCT] Attributi
FROM Tabella TipoJoin JOIN Tabella ON CondizioneDiJoin
[WHERE CondizioniDiTupla];
dove le tipologie di join possono essere INNER o [FULL | LEFT | RIGHT] OUTER. Le differenze tra le varie combinazioni possibili le potete vedere nell’immagine sottostante.
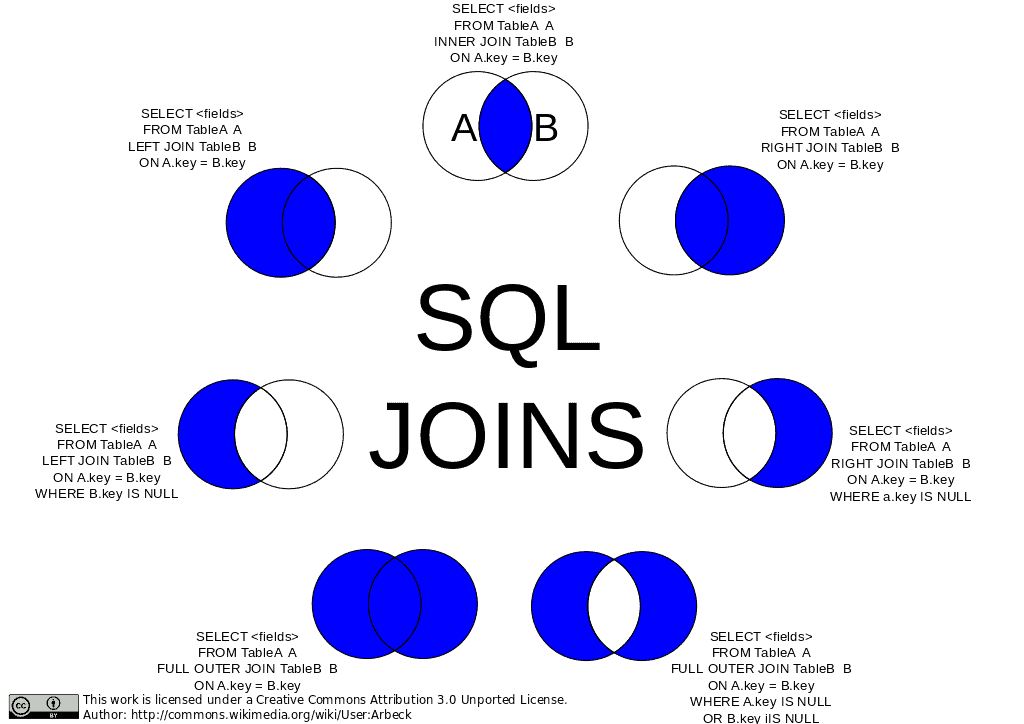
GROUP BY
Se avete seguito fino a questo punto questo articolo e quelli precedenti, ora siete in grado di filtrare i dati con predicati semplici e mettere insieme contenuti che arrivano da tabelle diverse. Ci manca un tassello fondamentale in molti scenari: creare gruppi all’interno dei nostri dati. Per far ciò è necessario usare la clausola GROUP BY. La sua sintassi è davvero semplice:
GROUP BY ElencoAttributiDiRaggruppamento
L’ordine degli attributi di raggruppamento è ininfluente, ma la loro presenza implica ciò che si può includere nella clausola della SELECT. Infatti, solo gli attributi definiti nella clausola GROUP BY possono comparire nella clausola SELECT. Quindi come facciamo a mostrare altre informazioni? Per visualizzare altri campi è sufficiente inserirli nella clausola GROUP BY. Se questi campi sono univocamente determinati da attributi già presenti nella clausola GROUP BY, essi non altereranno la definizione dei gruppi.
Ma allora cosa servono i gruppi se non a eliminare valori duplicati che si potevano fare anche con la keyword DISTINCT nella SELECT? I gruppi definiti servono per calcolare funzioni aggregati su tutti gli altri attributi che non sono stati inclusi nella clausola GROUP BY. Possiamo così sapere quanti elementi ci sono in ciascun gruppo, calcolare la media, il valore minimo e/o massimo di un campo, e anche trovare il totale di un campo.
Vediamo quindi un esempio! Supponiamo di voler calcolare il numero di proiezioni, il numero di cinema diversi e di sale diverse per ciascun film. La query sarà la seguente:
SELECT Titolo, COUNT(*) AS NumProiezioni,
COUNT (DISTINCT CodC) AS NumCinema
COUNT(DISTINCT CodC, NumeroSala) AS NumSale
FROM PROIEZIONE P, FILM F
WHERE P.CodF=F.CodF
GROUP BY F.CodF, Titolo;
Come potete notare nella clausula GROUP BY sono stati inseriti sia il codice del film che il titolo, ma nella SELECT solo il titolo. Perché? La risposta è legata alla possibilità che due film abbiano lo stesso titolo (ad esempio i remake). Per evitare di raggruppare erroneamente due film basandoci solo sul titolo, si è incluso il codice che è univoco. A questo punto tutte le informazioni (campi) del film possono essere aggiunti senza alterare il risultato.
Altra osservazione da fare sono sui diversi impieghi della funzione COUNT. Nel primo caso abbiamo usato il COUNT(*) in quanto dovevamo contare il numero di elementi di ciascun gruppo che corrispondevano alle proiezioni di un film. Negli altri due casi abbiamo usato la keyword DISTINCT per contare rispettivamente i cinema e il numero di sale. L’uso opportuno delle combinazioni dei campi ci permette di calcolare cose diverse! Pertanto, il significato del risultato della funzione COUNT dipende dal contesto e dai parametri passati.
HAVING
La definizione dei gruppi è molto utile per estrarre alcune statistiche. In molti casi, però, non ci interessano tutti i gruppi ma solo quelli con determinate caratteristiche. Si possono quindi filtrare? Sì mediante la clausola HAVING. La sintassi è veramente semplice.
HAVING CondizioniGruppo
Le condizioni di gruppo possono essere solo funzioni aggregate. Quindi, non pensate mai di inserire condizioni di gruppo o funzione aggregate nella clausola WHERE, in quanto quest’ultima accetta solo predicati riferiti al singolo record.
Vediamo perciò un esempio di applicazione della clausola HAVING. Vogliamo adesso visualizzare le informazioni (nome e indirizzo) dei cinema di Roma che hanno una capienza complessiva tra tutte le sale a loro disposizione inferiore a 200 posti. La query sarà la seguente:
SELECT Nome, Indirizzo
FROM CINEMA C, SALA S
WHERE C.CodC=S.CodC
AND Città=’Roma’
GROUP BY CodC, Nome, Indirizzo
HAVING SUM(Capienza) < 200;
Anche in questo caso nella clausola GROUP BY abbiamo usato la chiave del cinema per definire i gruppi ed aggiunto gli altri campi (Nome e Indirizzo) che ci servivano nella clausola SELECT. La condizione di gruppo relativamente alla capienza complessiva è, invece, verificata mediante la clausola HAVING e la funzione di aggregazione SUM applicata al campo Capienza.


