
In article Elasticsearch: use of match queries we looked at how to query text fields of documents saved within an Elasticsearch index. In this article we will look, however, at term level queries that are used to query structured data, that is, searching for documents that match for exact values. We will also see how to change the score calculation and sort the results.
We will use the same data seen in the other article. Therefore, we recommend reading it to install the Elasticsearch stack on your PC via the Docker repository and import the data correctly.
Below are the main query examples covered in the guide for quick reference:
| Category | Type | Match criteria | Query | Match | No match |
|---|---|---|---|---|---|
| term | term | The query is applied to the generated tokens Since no analysis is performed, the keyword is searched as an exact match | tasty | 1. the food was tasty | 1. the food was Tasty |
| 2. the food was TASTY | |||||
| exists | term | Returns documents that contain an indexed value for a field | exists:{ "field":"name" } | Returns all documents that have the "name" field. | N/A |
| range | term | Returns documents that contain values within the range specified in the applied field | age:{ "gte": 20, "lte":30 } | Returns all documents whose value of the "age" field is between 20 and 30 (including 20 and 30) | N/A |
| ids | term | Returns the documents that have the specified document ids | N/A | N/A | N/A |
| prefix | term | Search for the exact term (including prefix) at the beginning of a word | Mult | 1. Multi | 1. multi |
| 2. Multiple | |||||
| 3. Multiply | |||||
| 4. Multiplication | |||||
| wildcard | term | Find all terms with the given wildcard pattern | c*a | 1. china | 1. cabbage |
| 2. canada | |||||
| 3. cambogia | |||||
| regex | term | Find terms with the indicated regex pattern | res[a-z]* | 1. restaurant | 1. res123 |
| 2. research | |||||
| fuzzy | term | Returns documents that contain terms similar to the search term | Sao Paulo | São Paulo | Chennai |
Term Query
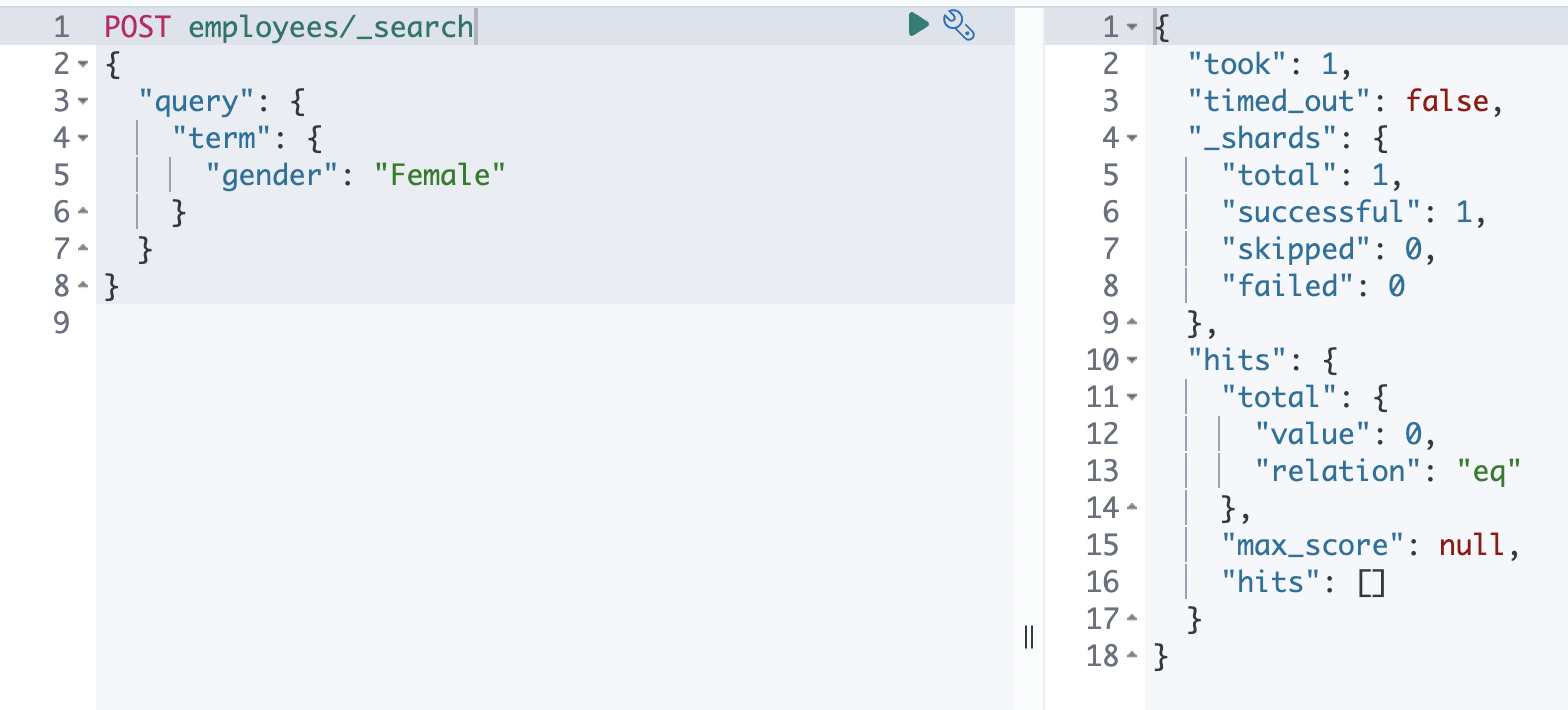
This is the simplest of the term-level queries. This query looks for the exact match of the searched keyword with the field in the document.
For example, if you search for the word “Female” using the term-level query against the field “gender,” it will search exactly as the word is, even with the boxes.
This can be demonstrated by the following two queries:
In the case above, the only difference between the two queries is the character of the search keyword. Case 1 had all lowercase letters, which were found because that is how they were saved with respect to the field. Case 2, on the other hand, had no search results because there was no such token in the field “gender” with an uppercase “F.”
We can also pass multiple terms to search on the same field, using the term query. Let’s search for “female” and “male” in the gender field. For this, we can use the term query as follows:
POST employees/_search
{
"query": {
"terms": {
"gender": [
"female",
"male"
]
}
}
} Query exists
Sometimes it happens that there is no indexed value for a field or that the field does not exist in the document. In these cases, indexing helps to identify such documents and analyze their impact.
For example, we index a document like the one below in the “employees” index.
PUT employees/_doc/5
{
"id": 5,
"name": "Michael Bordon",
"email": "[email protected]",
"gender": "male",
"ip_address": "10.47.210.65",
"date_of_birth": "12/12/1995",
"position": "Resources Manager",
"experience": 12,
"country": null,
"phrase": "Emulation of roots heuristic coherent systems",
"salary": 300000
} This document has no field named “company” and the value of the “country” field is null.
Now, if we want to find the documents with the field “company”, we can use the exist query as follows:
GET employees/_search
{
"query": {
"exists": {
"field": "company"
}
}
} The previous query lists all documents that have the “company” field.
Perhaps a more useful solution would be to list all documents without the “company” field. This can be achieved by using the exist query as follows
GET employees/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "company"
}
}
]
}
}
} The bool query will be explained in another article.
For convenience and uniformity, we delete the document now entered from the index by typing the following query
DELETE employees/_doc/5 Query range
Another widely used query in the Elasticsearch world is the range query. The range query allows us to get the documents that contain the terms within the specified range. The range query is a term-level query (meaning it is used to query structured data) and can be used for numeric fields, date fields, etc.
Query range on numeric fields
For example, in the dataset we created, if we need to filter out people who have an experience level between 5 and 10 years, we can apply the following interval query:
POST employees/_search
{
"query": {
"range" : {
"experience" : {
"gte" : 5,
"lte" : 10
}
}
}
} What is meant by gte, gt, lt, and lt?
- gte: greater than or equal to a given value
- gt: strictly greater than a given value
- lte: less than or equal to a given value
- lt: strictly less than a given value
Query range on date fields
Similarly, range queries can also be applied to date fields. If we need to find those born after 1986, we can run a query like the one below:
GET employees/_search
{
"query": {
"range" : {
"date_of_birth" : {
"gte" : "01/01/1986"
}
}
}
} Documents that have date_of_birth fields only after the year 1986 will be retrieved.
Query ids
The ids query is a relatively little-used query, but it is one of the most useful and therefore deserves to be included in this list. There are occasions when it is necessary to retrieve documents based on their ids. This can be achieved with a single get query, such as the one below:
GET indexname/typename/documentId This may be a good solution if there is only one document to retrieve based on an id, but what if we have many more?
In this case, the ids query is very useful. With the ids query, we can do all this in a single query.
In the following example, we are retrieving documents with IDs 1 and 4 from the employee index with a single query.
POST employees/_search
{
"query": {
"ids" : {
"values" : ["1", "4"]
}
}
} Query prefix
The prefix query is used to retrieve the documents that contain the given search string as prefix in the specified field.
Suppose we need to retrieve all documents that contain “at” as a prefix in the “name” field, then we can use the prefix query as follows:
GET employees/_search
{
"query": {
"prefix": {
"name": "al"
}
}
} The result is as follows.
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": 1,
"_source": {
"id": 4,
"name": "Alan Thomas",
"email": "[email protected]",
"gender": "male",
"ip_address": "200.47.210.95",
"date_of_birth": "11/12/1985",
"company": "Yamaha",
"position": "Resources Manager",
"experience": 12,
"country": "China",
"phrase": "Emulation of roots heuristic coherent systems",
"salary": 300000
}
}
]
}
}
Since the prefix query is a term query, it will pass the search string as is. Thus, the search for “al” and “Al” is different. If we search for “Al” in the above example, we will get 0 results because there is no token starting with “Al” in the inverted index of the “name” field. But if we query the field “name.keyword” with “Al”, we will get the above result and, in this case, the query for “al” will produce zero results.
Query wildcard
We select documents that have terms that match the indicated wildcard pattern.
For example, we search for “c*a” using the wildcard on the “country” field as below:
GET employees/_search
{
"query": {
"wildcard": {
"country": {
"value": "c*a"
}
}
}
} The above query retrieves all documents with the name “country” beginning with “c” and ending with “a” (for example: China, Canada, Cambodia, etc.).
The * operator can match zero or more characters.
Regexp
It is similar to the “wildcard” query seen above, but accepts regular expressions as input and retrieves matching documents.
GET employees/_search
{
"query": {
"regexp": {
"position": "res[a-z]*"
}
}
} The above query will give us the documents corresponding to the words that match the regular expression res[a-z]*.
Fuzzy
Fuzzy query can be used to return documents that contain terms similar to the search term. It is especially useful when dealing with spelling errors.
We can get results even if we search for “Chnia” instead of “China” using fuzzy query.
Let’s look at an example:
GET employees/_search
{
"query": {
"fuzzy": {
"country": {
"value": "Chnia",
"fuzziness": "2"
}
}
}
} Here the fuzziness is the maximum allowed edit distance for the match. You can also use parameters such as “max_expansions” etc. that we saw in the “match_phrase” query. More documentation on this can be found here
Fuzzy queries can also be used with “match” query types. The following example shows the use of fuzzy in a multi_match query
POST employees/_search
{
"query": {
"multi_match" : {
"query" : "heursitic reserch",
"fields": ["phrase","position"],
"fuzziness": 2
}
},
"size": 10
} The previous query will return documents matching “heuristic” or “research,” despite the spelling errors in the query.
Boosting
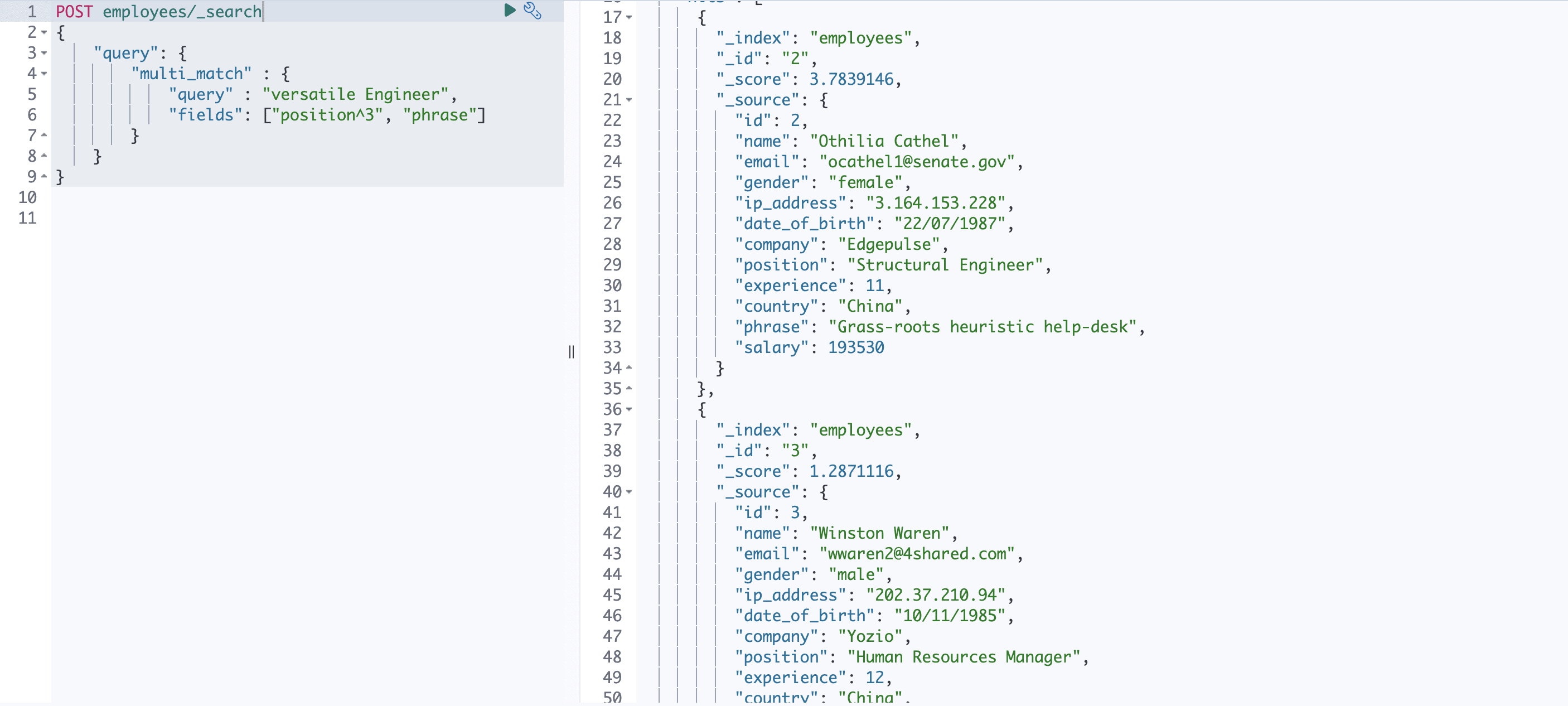
When querying, it is often useful to get the most favored results first. The easiest way to do this is called boosting in Elasticsearch. This is useful when querying multiple fields. For example, consider the following query:
POST employees/_search
{
"query": {
"multi_match" : {
"query" : "versatile Engineer",
"fields": ["position^3", "phrase"]
}
}
} This will return the response with the documents that match the “position” field at the top rather than those in the “phrase” field.
Sorting
When no sort parameter is specified in the search query, Elasticsearch returns the document based on the decreasing values of the “_score” field. This “_score” is calculated based on the match level of the query, using Elasticsearch’s default scoring methodologies. In all the examples discussed above, the same behavior can be seen in the results.
Only when using the “filter” context is the score not calculated, so that the results are returned faster.
Using query match
GET employees/_search
{
"_source": ["country"],
"query": {
"match" : {
"country" : "China"
}
}
} Use of context filter
GET employees/_search
{
"_source": ["country"],
"query": {
"bool" : {
"filter": {
"match": {
"country" : "China"
}
}
}
}
}
How to sort by a field
Elasticsearch provides the ability to sort by a field. For example, we need to sort employees by descending order of experience. To do this, we can use the following query with the sort option enabled:
GET employees/_search
{
"_source": ["name","experience","salary"],
"sort": [
{
"experience": {
"order": "desc"
}
}
]
} The results of the query are given below:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
12
]
},
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
12
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
11
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
7
]
}
]
}
} As can be seen from the previous answer, the results are sorted by decreasing values of employee experience.
In addition, there are two employees who have the same experience level as 12.
How to sort by multiple fields
In the previous example, we saw that there are two employees with the same experience level of 12, but we need to sort again by descending order of salary. We can also provide multiple fields for sorting, as shown in the query illustrated below:
GET employees/_search
{
"_source": [
"name",
"experience",
"salary"
],
"sort": [
{
"experience": {
"order": "desc"
}
},
{
"salary": {
"order": "desc"
}
}
]
} Now we get the following results:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
12,
300000
]
},
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
12,
50616
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
11,
193530
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
7,
180025
]
}
]
}
} In the results above, we can see that among the employees with the same experience level, the one with the highest salary was promoted first in the order (Alan and Winston had the same experience level, but unlike the results of the previous search, here Alan was promoted because he had a higher salary).
Note: If we change the order of the sorting parameters in the sorted array, that is, if we keep the “salary” parameter first and then the “experience” parameter, the search results will also change. The results will be sorted first by the “salary” parameter and then the “experience” parameter will be considered, without affecting the sorting based on salary.
We reverse the sort order of the above query, i.e. “salary” is kept first and “experience” as shown below:
GET employees/_search
{
"_source": [
"name",
"experience",
"salary"
],
"sort": [
{
"salary": {
"order": "desc"
}
},
{
"experience": {
"order": "desc"
}
}
]
} The results will be as follows:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
300000,
12
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
193530,
11
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
180025,
7
]
},
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
50616,
12
]
}
]
}
}
It can be seen that the candidate with experience value 12 ranked below the candidate with experience value 7, as the latter had a higher salary than the former.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
One Response