
Nell’articolo Elasticsearch: uso delle match query abbiamo analizzato come interrogare i campi testuali dei documenti salvati all’interno di un indice di Elasticsearch. In questo articolo analizzeremo, invece, le query term level che sono utilizzate per interrogare i dati strutturati, ossia la ricerca dei documenti che matchano per valori esatti. Vedremo anche come cambiare il calcolo dello score e ordinare i risultati.
Useremo gli stessi dati visti nell’altro articolo. Pertanto, vi consigliamo di leggerlo per installare lo stack di Elasticsearch sul vostro PC mediante il repository Docker e importare correttamente i dati.
Di seguito riportiamo i principali esempi di query trattati nella guida, per un rapido riferimento:
| Categoria | Tipo | Criteri di match | Query | Match | No match |
|---|---|---|---|---|---|
| term | term | La query viene applicata ai token generati Poiché non viene eseguita alcuna analisi, la parola chiave viene cercata come corrispondenza esatta | tasty | 1. the food was tasty | 1. the food was Tasty |
| 2. the food was TASTY | |||||
| exists | term | Restituisce i documenti che contengono un valore indicizzato per un campo | exists:{ "field":"name" } | restituisce tutti i documenti che hanno il campo "name". | N/A |
| range | term | Restituisce i documenti che contengono valori all'interno dell'intervallo specificato nel campo applicato | age:{ "gte": 20, "lte":30 } | restituisce tutti i documenti il cui valore del campo "age" è compreso tra 20 e 30 (inclusi 20 e 30) | N/A |
| ids | term | restituisce i documenti che hanno gli id dei documenti specificati | N/A | N/A | N/A |
| prefix | term | Cerca il termine esatto (compreso il prefisso) all'inizio di una parola | Mult | 1. Multi | 1. multi |
| 2. Multiple | |||||
| 3. Multiply | |||||
| 4. Multiplication | |||||
| wildcard | term | Trova tutti i termini con lo schema wildcard dato | c*a | 1. china | 1. cabbage |
| 2. canada | |||||
| 3. cambogia | |||||
| regex | term | Trova i termini con il modello regex indicato | res[a-z]* | 1. restaurant | 1. res123 |
| 2. research | |||||
| fuzzy | term | Restituisce i documenti che contengono termini simili al termine di ricerca | Sao Paulo | São Paulo | Chennai |
Term Query
È la più semplice delle query a livello di termine. Questa query cerca la corrispondenza esatta della parola chiave ricercata con il campo del documento.
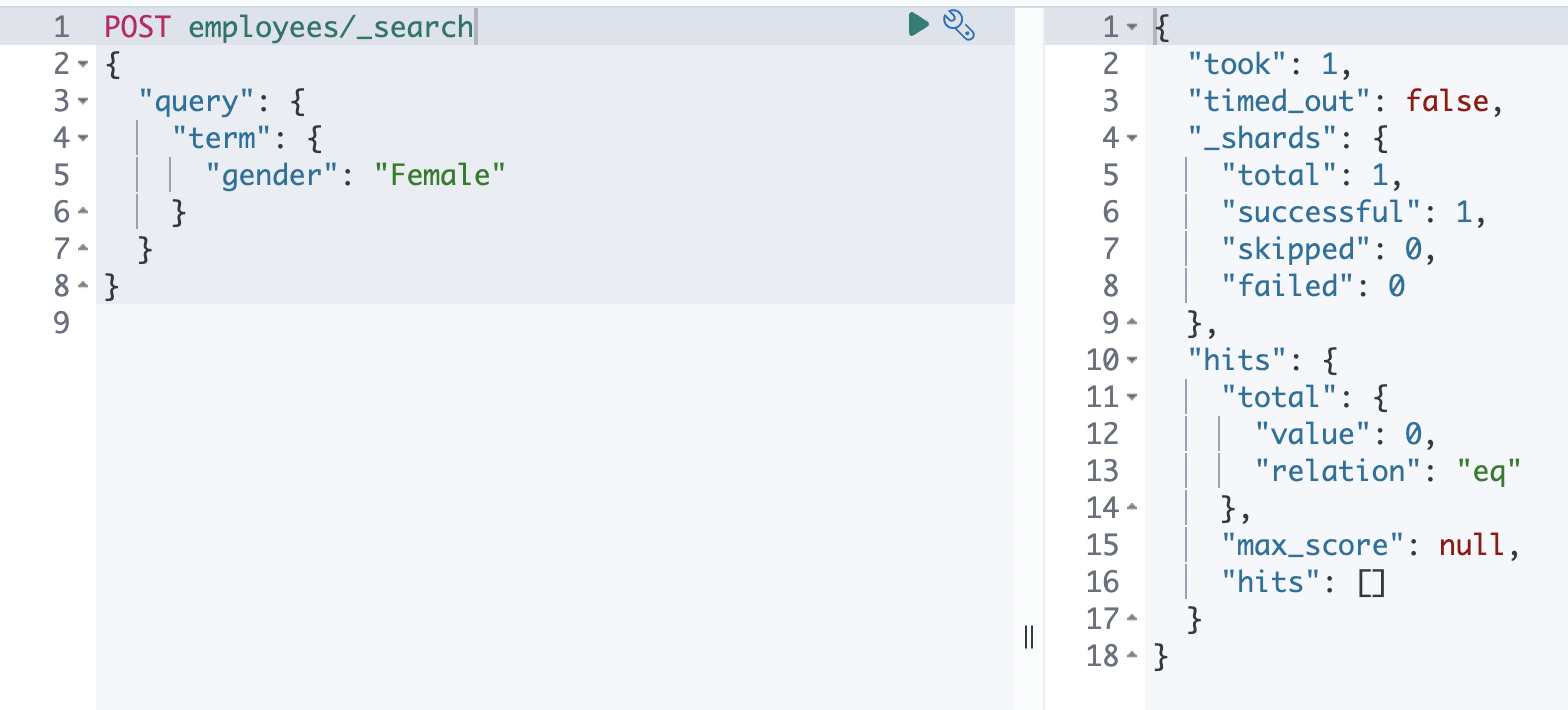
Ad esempio, se si cerca la parola “Female” utilizzando la query a livello di termine rispetto al campo “gender”, la ricerca verrà effettuata esattamente come la parola è, anche con le caselle.
Questo può essere dimostrato dalle due query seguenti:
Nel caso precedente, l’unica differenza tra le due query è il carattere della parola chiave di ricerca. Il caso 1 aveva tutte le lettere minuscole, che sono state trovate perché è così che sono state salvate rispetto al campo. Nel caso 2, invece, la ricerca non ha ottenuto alcun risultato, perché non esisteva un token simile nel campo “gender” con la “F” maiuscola.
Possiamo anche passare più termini da ricercare sullo stesso campo, utilizzando la query dei termini. Cerchiamo “female” e “male” nel campo gender. Per questo, possiamo usare la query dei termini come segue:
POST employees/_search
{
"query": {
"terms": {
"gender": [
"female",
"male"
]
}
}
} Query exists
A volte capita che non ci sia un valore indicizzato per un campo o che il campo non esista nel documento. In questi casi, l’indicizzazione aiuta a identificare tali documenti e ad analizzarne l’impatto.
Ad esempio, indicizziamo un documento come quello qui sotto nell’indice “employees”.
PUT employees/_doc/5
{
"id": 5,
"name": "Michael Bordon",
"email": "[email protected]",
"gender": "male",
"ip_address": "10.47.210.65",
"date_of_birth": "12/12/1995",
"position": "Resources Manager",
"experience": 12,
"country": null,
"phrase": "Emulation of roots heuristic coherent systems",
"salary": 300000
} Questo documento non ha un campo chiamato “company” e il valore del campo “country” è nullo.
Ora, se vogliamo trovare i documenti con il campo “company”, possiamo usare la query exist come segue:
GET employees/_search
{
"query": {
"exists": {
"field": "company"
}
}
} La query precedente elenca tutti i documenti che hanno il campo “azienda”.
Forse una soluzione più utile sarebbe quella di elencare tutti i documenti senza il campo “azienda”. Questo può essere ottenuto utilizzando la query exist come segue
GET employees/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "company"
}
}
]
}
}
} La query bool sarà spiegata in un altro articolo.
Per comodità e uniformità, cancelliamo dall’indice il documento ora inserito, digitando la richiesta seguente
DELETE employees/_doc/5 Query range
Un’altra query molto utilizzata nel mondo di Elasticsearch è la query range. La query di range ci permette di ottenere i documenti che contengono i termini all’interno dell’intervallo specificato. La query range è una query a livello di termine (significa che si usa per interrogare dati strutturati) e può essere usata per campi numerici, campi data, ecc.
Query range su campi numerici
Ad esempio, nel set di dati che abbiamo creato, se dobbiamo filtrare le persone che hanno un livello di esperienza compreso tra 5 e 10 anni, possiamo applicare la seguente query di intervallo:
POST employees/_search
{
"query": {
"range" : {
"experience" : {
"gte" : 5,
"lte" : 10
}
}
}
} Cosa si intende per gte, gt, lt e lt?
- gte: maggiore o uguale a un determinato valore
- gt: strettamente maggiore a un determinato valore
- lte: minore o uguale a un determinato valore
- lt: strettamente minore a un determinato valore
Query range sui campi data
In modo analogo, le query range possono essere applicate anche ai campi data. Se abbiamo bisogno di trovare coloro che sono nati dopo il 1986, possiamo eseguire una query come quella riportata di seguito:
GET employees/_search
{
"query": {
"range" : {
"date_of_birth" : {
"gte" : "01/01/1986"
}
}
}
} Verranno recuperati i documenti che hanno i campi date_of_birth solo dopo l’anno 1986.
Query ids
La query ids è una query relativamente poco utilizzata, ma è una delle più utili e quindi merita di essere inserita in questo elenco. Ci sono occasioni in cui è necessario recuperare i documenti in base ai loro ID. Questo può essere ottenuto con una singola richiesta get, come quella riportata di seguito:
GET indexname/typename/documentId Questa può essere una buona soluzione se c’è un solo documento da recuperare in base a un ID, ma se ne abbiamo molti altri?
In questo caso, la query ids è molto utile. Con la query Ids, possiamo fare tutto questo in una singola richiesta.
Nell’esempio seguente, stiamo recuperando i documenti con gli ID 1 e 4 dall’indice dei dipendenti con una sola richiesta.
POST employees/_search
{
"query": {
"ids" : {
"values" : ["1", "4"]
}
}
} Query prefix
La query prefix viene utilizzata per recuperare i documenti che contengono la stringa di ricerca data come prefisso nel campo specificato.
Supponiamo di dover recuperare tutti i documenti che contengono “al” come prefisso nel campo “name”, allora possiamo usare la query prefix come segue:
GET employees/_search
{
"query": {
"prefix": {
"name": "al"
}
}
} Il risultato è il seguente
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": 1,
"_source": {
"id": 4,
"name": "Alan Thomas",
"email": "[email protected]",
"gender": "male",
"ip_address": "200.47.210.95",
"date_of_birth": "11/12/1985",
"company": "Yamaha",
"position": "Resources Manager",
"experience": 12,
"country": "China",
"phrase": "Emulation of roots heuristic coherent systems",
"salary": 300000
}
}
]
}
}
Poiché la query con prefisso è una query di termine, passerà la stringa di ricerca così come è. Quindi, la ricerca di “al” e “Al” è diversa. Se nell’esempio precedente cerchiamo “Al”, otterremo 0 risultati perché non c’è nessun token che inizia con “Al” nell’indice invertito del campo “name”. Ma se interroghiamo il campo “name.keyword” con “Al”, otterremo il risultato di cui sopra e, in questo caso, l’interrogazione per “al” produrrà zero risultati.
Query wildcard
Selezioniamo i documenti che hanno termini che corrispondono allo schema wildcard indicato.
Ad esempio, cerchiamo “c*a” utilizzando il carattere jolly sul campo “country” come di seguito:
GET employees/_search
{
"query": {
"wildcard": {
"country": {
"value": "c*a"
}
}
}
} La query di cui sopra recupera tutti i documenti con il nome “country” che inizia con “c” e termina con “a” (ad esempio: Cina, Canada, Cambogia, ecc.).
L’operatore * può corrispondere a zero o più caratteri.
Regexp
È simile alla query “wildcard” vista in precedenza, ma accetta come input le espressioni regolari e recupera i documenti corrispondenti.
GET employees/_search
{
"query": {
"regexp": {
"position": "res[a-z]*"
}
}
} La query di cui sopra ci fornirà i documenti corrispondenti alle parole che corrispondono all’espressione regolare res[a-z]*.
Fuzzy
La query Fuzzy può essere utilizzata per restituire i documenti che contengono termini simili a quelli del termine di ricerca. È particolarmente utile quando si tratta di errori di ortografia.
Possiamo ottenere risultati anche se cerchiamo “Chnia” invece di “Cina”, utilizzando la query fuzzy.
Vediamo un esempio:
GET employees/_search
{
"query": {
"fuzzy": {
"country": {
"value": "Chnia",
"fuzziness": "2"
}
}
}
} Qui la fuzziness è la massima distanza di modifica consentita per la corrispondenza. Si possono usare anche parametri come “max_expansions” ecc. che abbiamo visto nella query “match_phrase”. Una maggiore documentazione al riguardo si trova qui
Le query fuzzy possono essere utilizzate anche con i tipi di query “match”. L’esempio seguente mostra l’utilizzo della fuzzy in una query multi_match
POST employees/_search
{
"query": {
"multi_match" : {
"query" : "heursitic reserch",
"fields": ["phrase","position"],
"fuzziness": 2
}
},
"size": 10
} La query precedente restituirà i documenti corrispondenti a “heuristic” o “research”, nonostante gli errori ortografici della query.
Boosting
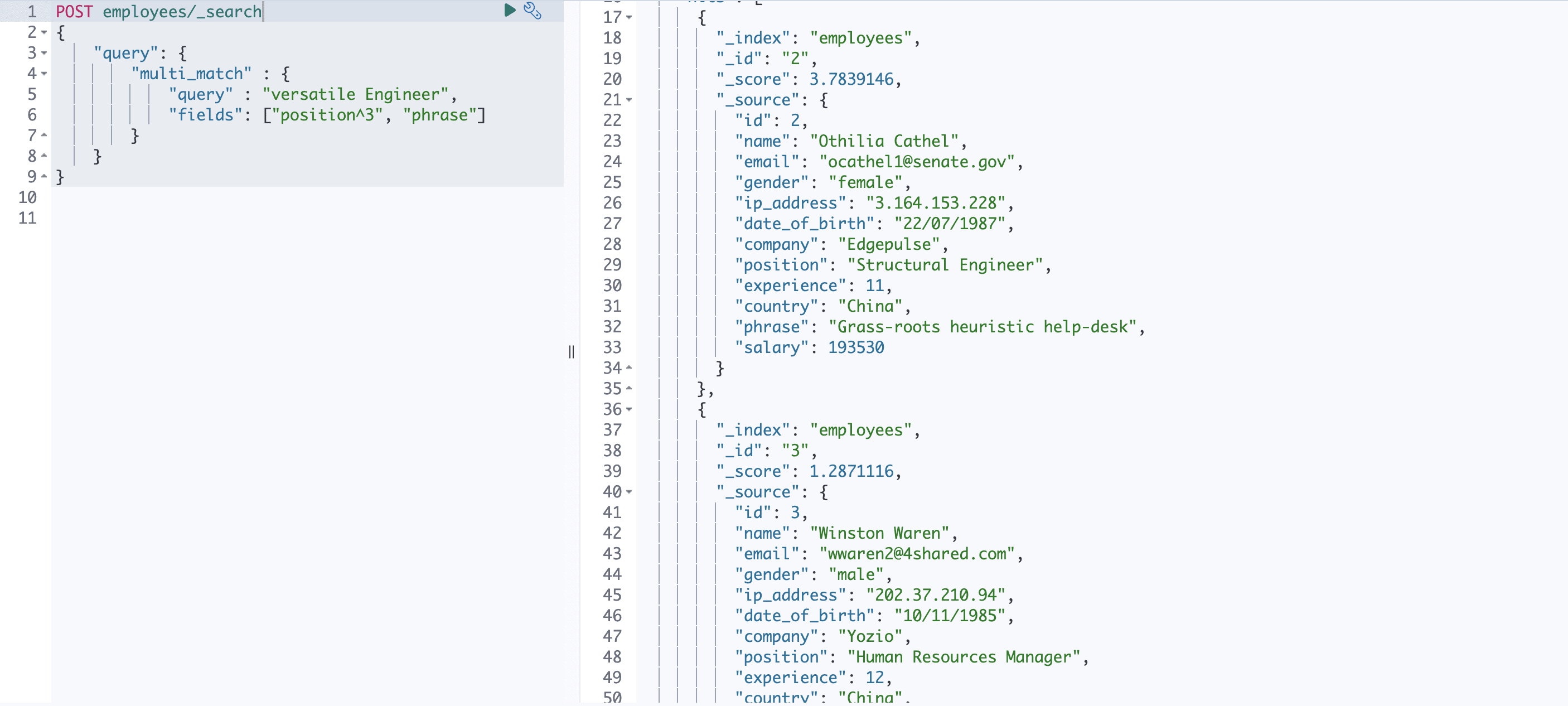
Durante l’interrogazione, spesso è utile ottenere prima i risultati più favoriti. Il modo più semplice per farlo è chiamato boosting in Elasticsearch. Questo è utile quando si interrogano più campi. Ad esempio, si consideri la seguente query:
POST employees/_search
{
"query": {
"multi_match" : {
"query" : "versatile Engineer",
"fields": ["position^3", "phrase"]
}
}
} Questo restituirà la risposta con i documenti che corrispondono al campo “position” in cima piuttosto che con quelli del campo “phrase”.
Sorting
Quando non viene specificato alcun parametro di ordinamento nella richiesta di ricerca, Elasticsearch restituisce il documento in base ai valori decrescenti del campo “_score”. Questo “_score” è calcolato in base al livello di corrispondenza della query, utilizzando le metodologie di punteggio predefinite di Elasticsearch. In tutti gli esempi discussi in precedenza si può notare lo stesso comportamento nei risultati.
Solo quando si utilizza il contesto “filter” non viene calcolato il punteggio, in modo da rendere più veloce la restituzione dei risultati.
Uso della query match
GET employees/_search
{
"_source": ["country"],
"query": {
"match" : {
"country" : "China"
}
}
} Utilizzo del contesto filter
GET employees/_search
{
"_source": ["country"],
"query": {
"bool" : {
"filter": {
"match": {
"country" : "China"
}
}
}
}
}
Come ordinare in base a un campo
Elasticsearch offre la possibilità di ordinare in base a un campo. Ad esempio, dobbiamo ordinare i dipendenti in base all’ordine decrescente di esperienza. Per farlo, possiamo utilizzare la query seguente con l’opzione di ordinamento abilitata:
GET employees/_search
{
"_source": ["name","experience","salary"],
"sort": [
{
"experience": {
"order": "desc"
}
}
]
} I risultati dell’interrogazione sono riportati di seguito:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
12
]
},
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
12
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
11
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
7
]
}
]
}
} Come si può vedere dalla risposta precedente, i risultati sono ordinati in base ai valori decrescenti dell’esperienza dei dipendenti.
Inoltre, ci sono due dipendenti che hanno lo stesso livello di esperienza di 12.
Come ordinare in base a più campi
Nell’esempio precedente, abbiamo visto che ci sono due dipendenti con lo stesso livello di esperienza di 12, ma abbiamo bisogno di ordinare nuovamente in base all’ordine decrescente dello stipendio. Possiamo anche fornire più campi per l’ordinamento, come mostrato nella query illustrata di seguito:
GET employees/_search
{
"_source": [
"name",
"experience",
"salary"
],
"sort": [
{
"experience": {
"order": "desc"
}
},
{
"salary": {
"order": "desc"
}
}
]
} Ora otteniamo i risultati seguenti:
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
12,
300000
]
},
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
12,
50616
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
11,
193530
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
7,
180025
]
}
]
}
} Nei risultati sopra riportati, si può notare che tra i dipendenti con lo stesso livello di esperienza, quello con lo stipendio più alto è stato promosso prima nell’ordine (Alan e Winston avevano lo stesso livello di esperienza, ma a differenza dei risultati della ricerca precedente, qui Alan è stato promosso perché aveva uno stipendio più alto).
Nota: se cambiamo l’ordine dei parametri di ordinamento nell’array ordinato, cioè se manteniamo prima il parametro “stipendio” e poi il parametro “esperienza”, anche i risultati della ricerca cambieranno. I risultati verranno ordinati prima in base al parametro “stipendio” e poi verrà preso in considerazione il parametro “esperienza”, senza influire sull’ordinamento basato sullo stipendio.
Invertiamo l’ordine di ordinamento della query di cui sopra, cioè “stipendio” viene mantenuto per primo e “esperienza” come mostrato di seguito:
GET employees/_search
{
"_source": [
"name",
"experience",
"salary"
],
"sort": [
{
"salary": {
"order": "desc"
}
},
{
"experience": {
"order": "desc"
}
}
]
} I risultati saranno i seguenti:
{
"took": 1,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 4,
"relation": "eq"
},
"max_score": null,
"hits": [
{
"_index": "employees",
"_id": "4",
"_score": null,
"_source": {
"name": "Alan Thomas",
"experience": 12,
"salary": 300000
},
"sort": [
300000,
12
]
},
{
"_index": "employees",
"_id": "2",
"_score": null,
"_source": {
"name": "Othilia Cathel",
"experience": 11,
"salary": 193530
},
"sort": [
193530,
11
]
},
{
"_index": "employees",
"_id": "1",
"_score": null,
"_source": {
"name": "Huntlee Dargavel",
"experience": 7,
"salary": 180025
},
"sort": [
180025,
7
]
},
{
"_index": "employees",
"_id": "3",
"_score": null,
"_source": {
"name": "Winston Waren",
"experience": 12,
"salary": 50616
},
"sort": [
50616,
12
]
}
]
}
}
Si può notare che il candidato con valore di esperienza 12 si è posizionato al di sotto del candidato con valore di esperienza 7, in quanto quest’ultimo aveva uno stipendio maggiore del primo.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
Una risposta