
In previous articles about Google Cloud we have analyzed various technologies provided by the platform. However, these technologies are not isolated from each other, but are integrated to build highly reliable, secure and innovative solutions. In the context of Big Data, a fundamental aspect of great interest are the Data Lakes.
What is a Data Lake? It’s a fairly broad term, but generally describes a centralized repository that allows you to store, securely, large amounts of data in its native format from many diverse and inhomogeneous sources.
Data lakes are typically used to drive data analytics, Machine Learning workflows, or batch and streaming pipelines.
But where do data lakes fit in relation to an overall data management and analysis project? The project starts with one or more data sources. It’s the data engineer’s job to build reliable ways to retrieve and store that data. Once the data extraction processes are defined, the data must be stored in so-called data sinks. Possible solutions are data lakes or data warehouses. In many cases, however, the data needs cleaning and processing processes so that it can be used in a simple, intuitive, but above all efficient way. For this reason, data lakes are used. In general, only after the data has been cleaned and formatted will it be dumped into a data warehouse. Finally, once the data is saved in the data warehouse, it will be possible to analyze it to create Machine Learning models or simply dashboards for data visualization.
Before delving into the tools available in Google Cloud to build a data lake, let’s make a brief distinction between data lakes and data warehouses.
Differences between Data Lake and Data Warehouse
Below we summarize the main differences between a data lake and a data warehouse.
- Data Collection. Unlike the Data Warehouse, the Data Lake does not require ex ante structuring of the data. On the contrary, its strength lies in its ability to accommodate structured, semi-structured and unstructured data.
- Data processing. In the Data Warehouse, the structure of the database is defined a priori, the data is written in the predefined structure and then read in the desired format (Schema-on-write). In the Data Lake, instead, they are acquired in the native format and each element receives an identifier and a set of accompanying metadata (Schema-on-read).
- Agility and flexibility. Being a highly structured repository, changing the structure of a Data Warehouse can be very time consuming. A Data Lake, on the other hand, allows you to easily configure and reconfigure models, queries, and live apps, and proceed to Data Analytics in a more flexible manner.
Architecture example
Let’s show an example of an architecture based on Google Cloud. The data lake here is Cloud Storage, right in the middle of the diagram.

It’s usually a well-established option for raw data, as it’s durable and highly available, but that doesn’t mean it’s the only option for creating a data lake in GCP. In other cases, BigQuery could be used as both a data lake and a data warehouse. This is why it’s so important to figure out what you want to do first, and then find which solutions best meet the needs of the problem. Regardless of what tools and technologies you use in the cloud, data lakes can be thought of as an enduring staging area where everything is collected and then shipped elsewhere.
Data can end up in dozens of places, as a transformation pipeline cleans it up and moves it to the data warehouse. From there it can then be read by a machine learning model or visualization tool. The whole thing, however, starts with getting the data into the data lake.
To better understand the complexity that an architecture can achieve, here is an overview of Google Cloud products for Big Data. In the figure, the products are categorized by where they are likely to be used in a typical Big Data processing workflow. From storing the data on the left, to inserting it into the cloud’s native tools for analysis, training machine learning models, and finally making use of the data.
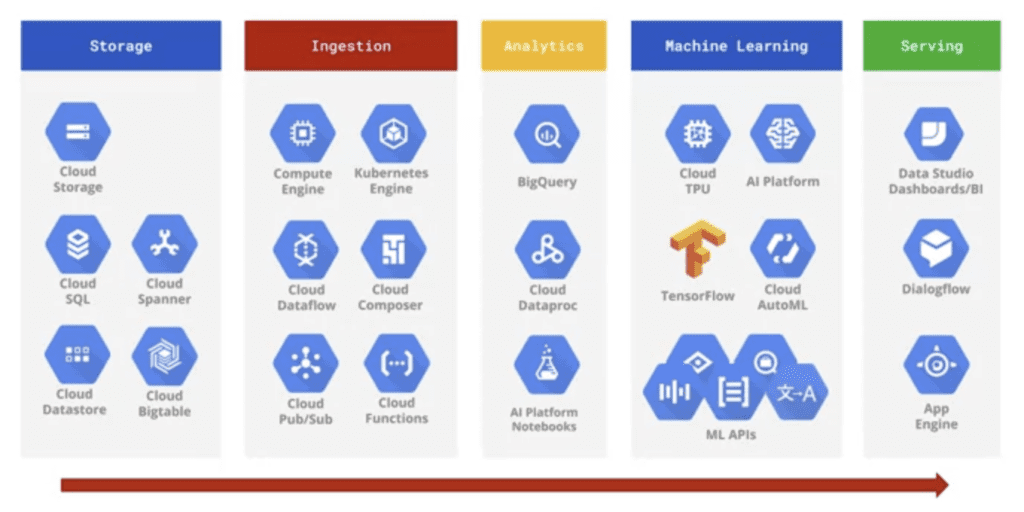
You might be surprised not to see BigQuery in the storage column. This is because, generally, BigQuery is used as a data warehouse. In fact, you need to remember the difference between data lake and data warehouse seen earlier. A data lake is essentially that place where you store data in its raw format, i.e. the one defined by your applications. In contrast, the data warehouse requires a very specific schema and use case. Therefore, the raw data needs to be cleaned up, transformed, organized, and processed before being stored within the data warehouse. For these reasons BigQuery which is optimized to store and query structured and semi-structured data is used as a data warehouse.
Building a data lake: what options?
The options made available to GCP for storage are as follows:
- Raw data:
- Relational Data:
- NoSQL data:
Choosing a technology from those proposed depends a lot on the use case and ultimately what you need to build. So how do you decide which technology is best for each case?
The choice depends on several factors, including the size of the data, the volume (an aspect of the 3 Vs of Big Data) and finally where it needs to be poured.
In architecture diagrams, the end point of the data is the data warehouse. One critical aspect should not be forgotten, which is the amount of processing and transformation the data needs before it is usable. At this point a question arises. When should I process the data? Before loading them into the data lake or after?
There is no one-size-fits-all answer! The method you use to load the data into the cloud depends on how much transformation is required for the raw data to be rendered in the final desired format. There are 3 alternatives shown in the figure.

The simplest case might be to already have the data in a format that is easily assimilated by the cloud product you want to store it in. For example, if the data is in an Avro format you could already store it directly in BigQuery. Other use cases include importing data from a database where the source and destination already have the same schema. This procedure is called EL: Extract and Load.
In some cases, however, this procedure is not sufficient. In fact, transformations may need to be applied. When the amount of transformation that is needed is not very high and the transformation will not reduce much the amount of data you have you can use the ELT process: Extract, Load and Transform. Basically you load the data directly into the final service, say BigQuery, and then run queries to transform the data and save the results in a new table.
When, however, the transformation is essential or reduces the size of the data or requires large computational resources, the ETL procedure is adopted: Extract, Transform and Load. This is the most common case since the original data is usually dirty and unstructured.


