
Negli articoli precedenti su Google Cloud abbiamo analizzato varie tecnologie fornite dalla piattaforma. Queste tecnologie però non sono isolate tra di loro, ma vengono integrate per costruire soluzione altamente affidabili, sicure ed innovative. Nell’ambito dei Big Data un aspetto fondamentale e di grande interesse sono i Data Lakes.
Cos’è un Data Lake? È un termine abbastanza ampio, ma generalmente descrive un repository centralizzato che consente di archiviare, in modo sicuro, grandi quantità di dati nel loro formato nativo, provenienti da molte fonti diversificate e disomogenee.
I data lakes sono tipicamente utilizzati per guidare l’analisi dei dati, i workflow di Machine Learning, o le pipeline di batch e di streaming.
Ma dove si posizionano i data lakes rispetto ad un progetto generale di gestione e analisi dei dati? Il progetto inizia con una o più fonti di dato. È compito dell’ingegnere dei dati costruire modi affidabili per recuperare e memorizzare quei dati. Una volta definiti i processi di estrazione dei dati, questi devono essere memorizzati nei cosiddetti data sinks. Le possibili soluzioni sono i data lakes o i data warehouses. In molti casi, però, i dati necessitano di processi di pulizia ed elaborazione affinché possano essere fruibili in modo semplice, intuitivo, ma soprattutto efficiente. Per questo motivo si usano i data lakes. In generale, solo dopo una pulizia e formattazione dei dati, questi verranno riversati in un data warehouse. Infine, una volta che i dati saranno salvati nel data warehouse, sarà possibile analizzarli per creare modelli di Machine Learning o semplicemente dashboard per la visualizzazione dei dati.
Prima di addentrarci sugli strumenti disponibili in Google Cloud per costruire un data lake facciamo una breve distinzione tra i data lakes e i data warehouse.
Differenze tra Data Lake e Data Warehouse
Di seguito riassumiamo le principali differenze tra un data lake e un data warehouse.
- Raccolta dei dati. A differenza del Data Warehouse, il Data Lake non necessita di una strutturazione ex ante del dato. Anzi, trova proprio nella capacità di accogliere dati strutturati, semi-strutturati e destrutturati il suo punto di forza.
- Elaborazione dei dati. Nel Data Warehouse viene definita a priori la struttura del database, i dati vengono scritti nella struttura predefinita e poi letti nel formato desiderato (Schema-on-write). Nel Data Lake, invece, sono acquisiti nel formato nativo e ogni elemento riceve un identificatore e un insieme di metadati a corredo (Schema-on-read).
- Agilità e flessibilità. Essendo un repository altamente strutturato, cambiare la struttura di un Data Warehouse può risultare molto dispendioso in termini di tempo. Un Data Lake, all’opposto, consente di configurare e riconfigurare facilmente modelli, query e app live e di procedere al Data Analytics in modo più flessibile.
Esempio di architettura
Riportiamo un esempio di architettura basata su Google Cloud. Il data lake qui è il Cloud Storage, proprio al centro del diagramma.

Di solito è un’opzione consolidata per i dati grezzi, poichè è durevole e altamente disponibile, ma ciò non significa che sia l’unica opzione per la creazione di un data lake in GCP. In altri casi, BigQuery potrebbe essere usato sia come data lake che data warehouse. Questo è il motivo per cui è così importante capire prima cosa si vuole fare, e poi trovare quali soluzioni soddisfano meglio le esigenze del problema. Indipendentemente da quali strumenti e tecnologie si usino nel cloud, i data lakes si possono pensare come ad un’area di sosta duratura dove tutto viene raccolto e poi spedito altrove.
I dati possono finire in doversi posti, come una pipeline di trasformazione che li ripulisce e li sposta nel data warehouse. Da qui possono essere poi letti da un modello di apprendimento automatico o da un tool di visualizzazione. Il tutto, però, inizia con l’inserimento dei dati nel data lake.
Per comprendere meglio la complessità che un’architettura po’ raggiungere, riportiamo una panoramica dei prodotti di Google Cloud per i Big Data. In figura i prodotti sono categorizzati in base a dove probabilmente verranno utilizzati in un tipico flusso di lavoro di elaborazione dei Big Data. Dall’archiviazione dei dati sulla sinistra, all’inserimento negli strumenti nativi del cloud per l’analisi, l’addestramento di modelli di apprendimento automatico e, infine, la fruizione dei dati.
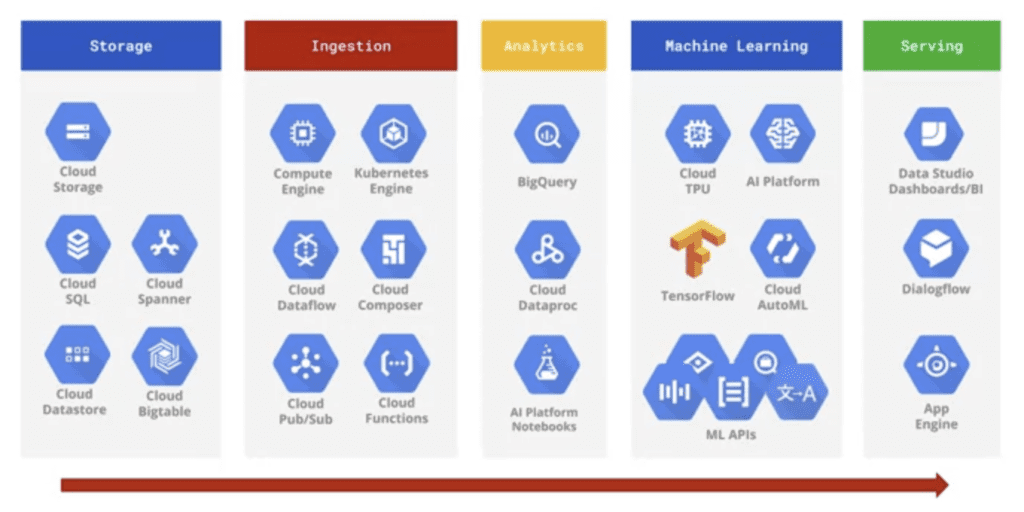
Potreste essere sorpresi di non vedere BigQuery nella colonna dello storage. Questo perché, generalmente, BigQuery è utilizzato come data warehouse. Infatti, bisogna ricordarsi la differenza tra data lake e data warehouse vista in precedenza. Un data lake è essenzialmente quel luogo dove si memorizzano i dati nel loro formato grezzo, ossia quello definito dalle applicazioni. Diversamente, il data warehouse richiede uno schema e un caso d’uso ben specifico. Pertanto, i dati grezzi devono essere ripuliti, trasformati, organizzati ed elaborati prima di essere salvati all’interno del data warehouse. Per questi motivi BigQuery che è ottimizzato per immagazzinare e interrogare dati strutturati e semi-strutturati è utilizzato come data warehouse.
Costruire un data lake: quali opzioni?
Le opzioni messe a disposizione di GCP per lo storage sono le seguenti:
- Dati grezzi:
- Dati relazionali:
- Dati NoSQL:
La scelta di una tecnologia tra quelle proposte dipende molto dal caso d’uso e, in definitiva, da ciò che bisogna costruire. Quindi come si fa a decidere quale tecnologia è la migliore per ciascun caso?
La scelta dipende da diversi fattori, tra cui la grandezza dei dati, il volume (aspetto delle 3 V dei Big Data) e infine dove devono essere riversati.
Nei diagrammi di architettura il punto di arrivo dei dati è il data warehouse. Non bisogna dimenticare un aspetto critico, ossia la quantità di elaborazione e trasformazione di cui i dati hanno bisogno prima che siano utilizzabili. A questo punto una domanda sorge spontanea. Quando devo effettuare l’elaborazione dei dati? Prima di caricarli nel data lake o dopo?
Non esiste una risposta unica! Il metodo che si usa per caricare i dati nel cloud dipende da quanta trasformazione è necessaria affinché i dati grezzi vengano resi nel formato finale desiderato. Esistono 3 alternative riportate in figura.

Il caso più semplice potrebbe essere quello di avere i dati già in un formato che sia facilmente assimilabile dal prodotto cloud in cui si vogliono memorizzare. Per esempio, se i dati sono in un formato Avro potreste già memorizzarli direttamente in BigQuery. Altri casi d’uso includono l’importazione di dati da un database dove la fonte e la destinazione hanno già lo stesso schema. Questa procedura viene definita EL: Extract e Load.
In alcuni casi però questa procedura non è sufficiente. Infatti, potrebbe essere necessario applicare delle trasformazioni. Quando la quantità di trasformazione che è necessaria non è molto alta e la trasformazione non ridurrà molto la quantità di dati che avete si può usare il processo ELT: Extract, Load e Transform. In pratica si caricano i dati direttamente nel servizio finale, ad esempio BigQuery, e poi si effettuano delle query per trasformare i dati e salvare i risultati in una nuova tabella.
Quando, però, la trasformazione è essenziale o riduce le dimensioni dei dati o richiede grandi risorse computazionali, si adotta la procedura ETL: Extract, Transform e Load. Questo è il caso più comune in quanto i dati originali sono di solito sporchi e poco strutturati.


