A differenza dei database relazionali, MongoDB permette di creare delle pipeline di manipolazione ed estrazione di statistiche in modo semplice ed intuitivo. Con le ultime versioni è stata introdotta l’aggregation pipeline che si basa sull’idea della creazione di un framework per l’elaborazione dei dati. I documenti di una collezione entrano in una pipeline a più fasi che trasforma i documenti in un risultato aggregato. Le operazioni in ciascuna fase permettono ad esempio di raggruppare i valori di più documenti insieme, calcolare statistiche e integrare informazioni provenienti da altri documenti con l’obiettivo di restituire un unico risultato.
In questo tutorial andremo ad esplorare alcune delle operazioni maggiormente usate e utili proposte dal framework di aggregazione mediante degli esempi. Sfrutteremo i database di esempio forniti con l’installazione gratuita di MongoDB Atlas e costruiremo le pipeline mediante l’interfaccia grafica fornita da MongoDB Compass. Per ottenere in modo completamente gratuito l’ambiente cloud per esercitarvi potete fare riferimento all’articolo MongoDB Atlas – creazione di un ambiente cloud per esercitarsi. Se invece avete già a disposizione il vostro MongoDB Atlas, potete far riferimento all’articolo MongoDB Compass – interrogare e analizzare in modo semplice un database NoSQL per scoprire come connettervi al cloud, esercitarvi con alcune interrogazioni e esercitarvi nell’utilizzo del tool MongoDb Compass.
Estrazione di statistiche
L’aggregation pipeline è usata molto spesso per estrarre statistiche. Per questo esempio si utilizzerà il database sample_training ed in particolare la collezione grades. Ogni documento di questa collezione contiene l’id dello studente, l’id della classe di appartenenza e un vettore di embedded documents costituiti a loro volta da un campo type e da uno score.
Se si volesse trovare la media dei voti per ciascun tipologia di score, è necessario utilizzare un aggregation pipeline. MongoDB Compass ci permette di creare l’aggregation pipeline in modo interattivo, verificando che il risultato di ciascun stage sia coretto sia sintatticamente che a livello di insieme di documenti restituiti. Per iniziare a familiarizzare con questa metodologia di estrazione dei dati o per testare query complesse questo è lo strumento migliore.

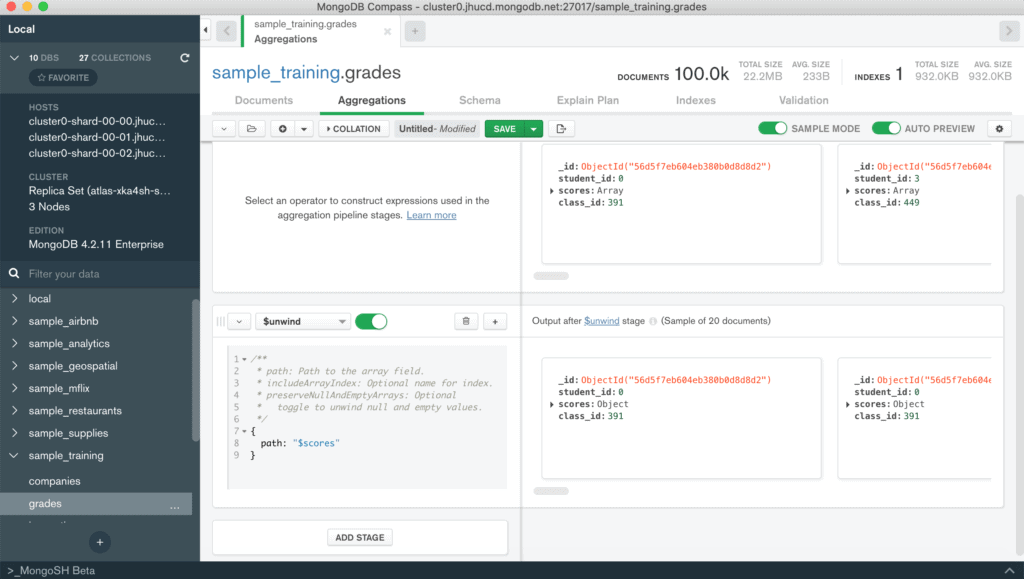
Tornando all’esempio, per prima cosa dobbiamo scompattare il vettore scores affinché il nostro calcolo venga effettuato su tutti gli score inclusi in ciascun documento. Per questo motivo si utilizza l’operatore $unwind. Come si può notare dalla figura, a sinistra si andrà a definire l’operatore e i parametri che vengono richiesti, mentre a destra, non appena il blocco della pipeline sarà configurato opportunamente, si otterrà un’anteprima dei documenti restituiti dallo stage in questione (l’opzione AUTO PREVIEW deve essere attiva). Lo stage sarà definito come segue:
{path: "$scores" } Attenzione
Il simbolo $ prima del nome dell'attributo viene usato per indicare che si vuole utilizzare i valori presenti all'interno del campo. Per l'operatore $unwind questo simbolo deve essere sempre presente.
Quello che si ottiene è un documento per ogni elemento del vettore scores. Ogni documento avrà gli stessi campi del documento originale ma il campo score sarà un embedded document relativo all’i-esimo elemento estratto.
A questo punto possiamo calcolare le statistiche di interesse definendo dei gruppi di interesse e specificando le misure da calcolare. L’operatore per effettuare questa operazione è $group. Si aggiunge quindi uno stage cliccando sul bottone ADD STAGE o sul pulsante + in alto a destra dello stage attuale. Come in precedenza, si andrà a selezionare l’operatore $group e a definire i suoi rispettivi parametri. Nel caso d’esempio è necessario raggruppare per score_types. Pertanto l’_id del documento in uscita dalla stage di $group sarà uguale al valore del campo score_type. Per calcolare la media andremo a definire un nuovo campo che sarà calcolato con l’operatore $avg relativamente ai valori contenuti nel path scores.score. Lo stage risulterà come segue:
{
_id: "$scores.type",
avg: {$avg: "$scores.score"}
} Ovviamente altre statistiche possono essere estratte come ad esempio il minimo, il massimo e il numero di elementi presenti in ciascun gruppo.
{
_id: "$scores.type",
avg: {$avg: "$scores.score"},
min: {$min: "$scores.score"},
max: {$max: "$scores.score"},
count: {$sum: 1}
} Attenzione
Per il conteggio del numero di elementi in ciascun gruppo si deve usare l'operatore $sum per incrementare di 1 un contatore ogni volta che un documento viene associato ad un gruppo. Questo perché l'operatore $count viene utilizzato per definire uno stage che conta il numero di documenti ricevuti in ingresso.
E’ possibile esportare la pipeline definita in alcuni linguaggi di programmazione (Python, Java, Node, C#) o semplicemente copiarla per poi usarla nella shell cliccando sul pulsante ![]() . Il risultato finale sarà il seguente:
. Il risultato finale sarà il seguente:
[{$unwind: {
path: '$scores'
}}, {$group: {
_id: '$scores.type',
avg: {
$avg: '$scores.score'
},
min: {
$min: '$scores.score'
},
max: {
$max: '$scores.score'
},
count: {
$sum: 1
}
}}]
Analisi dei quantili
La struttura dell’aggregation pipeline dell’esempio precedente può essere utilizzata ogni qualvolta è necessario estrarre alcune statistiche standard sulla distribuzione dei dati. A volte però è necessario calcolare i quantili.
In statistica il quantile di ordine α o α-quantili (con α un numero reale nell'intervallo [0,1]) è un valore qα che divide la popolazione in due parti, proporzionali ad α e (1-α) e caratterizzate da valori rispettivamente minori e maggiori di qα. Per poter calcolare un quantile di ordine α è necessario che il carattere sia almeno ordinato, cioè sia possibile definire un ordinamento sulle modalità.
Wikipedia
Esistono alcuni quantili, definiti di ordine semplice, che sono molto comuni in statistica. Tra questi ricordiamo:
- la mediana: ordine 1/2
- i quartili: ordini 1/4, 2/4 e 3/4
- i decili: di ordine m/10
- i centili (o percentili):, di ordine m/100.
Il calcolo di queste misure richiede di ordinare i dati di interesse per poi calcolare esattamente l’ordine del quantile corrispondente.
Per questo esempio utilizzeremo il database sample_airbnb e ci focalizzeremo sul calcolo di alcuni quantili legati al prezzo. In particolare calcoleremo la mediana, il primo e il quarto quartile, e il 95-esimo percentile.
Il primo passo è ordinare i dati presenti nella collezione.Utilizzeremo l’operatore $sort. In modo analogo alla funzione sort impiegata per ordinare i risultati della find, l’operatore $sort richiede un documento ordinato degli attributi su cui effettuare l’ordinamento. Per ciascuno di esso è obbligatorio inserire il verso dell’ordinamento (1 ascendente, -1 discendente). Nel nostro esempio dovremo ordinare il campo price in ordine ascendete come mostrato di seguito.
{$sort: {
price: 1
}} Per procedere al calcolo dei quantili, dobbiamo raggruppare tutti i valori del campo price in un vettore. In questo modo potremo sfruttare gli operatori di calcolo sui vettori per estrarre i valori dei quantili di interesse.
Bisogna quindi raggruppare tutti i documenti della collezione in un unico documento che conterrà un vettore value contenente tutti i valori di price ordinati. L’_id dell’operatore $group sarà impostato a null per ottenere un solo documento rappresentante l’intera collezione, mentre l’operatore $push inserirà il valore del campo price per ogni documento derivante dal passo precedente. L’ordinamento in base al prezzo verrà conservato poichè la lettura dei documenti avverrà in modo sequenziale. Lo stage di $group sarà definito come segue.
{$group: {
'_id': null,
'value': {'$push': '$price'}
}} Il calcolo dei quantili sarà effettuato mediante alcuni operatori matematici e di manipolazione dei vettori. In particolare, utilizzeremo gli operatori
Mediante l’operatore $size calcoleremo la dimensione del vettore value. Ovviamente era possibile estrarre questa informazione durante l’operazione di raggruppamento utilizzando l’operatore $sum. La dimensione del vettore dovrà essere moltiplicata per il valore del quantile di interesse. Ad esempio, se vogliamo calcolare la mediana bisognerà moltiplicarlo per 0.5, mentre per il primo quartile per 0.25, e così via.
Il risultato di questa moltiplicazione sarà la posizione all’interno del vettore dove troveremo il valore del quantile. Poiché la posizione deve essere un numero intero, dobbiamo assicurare che il valore restituito non contenga decimali mediante l’operatore $floor. Questo operatore prende il numero intero più grande inferiore o uguale al numero specificato. A questo è possibile estrarre il valore nella posizione calcolata dell’array corrispondente al quantile usando l’operatore $arrayElemAt.
Questi calcoli dovranno essere ripetuti per ciascun quantile da calcolare e inseriti all’interno di uno stage $project. Questo ultimo stage risulterà come segue.
{$project: {
_id: 0,
"0.25": {
$arrayElemAt:
["$value",
{$floor: {$multiply: [ 0.25, {$size: "$value"} ] } }
]
},
"median": {
$arrayElemAt:
["$value",
{$floor: {$multiply: [0.5, {$size: "$value"} ] } }
]
},
"0.75": {
$arrayElemAt:
["$value",
{$floor: {$multiply: [0.75, {$size: "$value"} ] } }
]
},
"95": {
$arrayElemAt:
["$value",
{$floor: {$multiply: [0.95, {$size: "$value"} ] } }
]
}
} Analisi temporali
MongoDB può essere usato per salvare dati relativi a serie temporali. Per ottenere le massime performance è necessario definire degli schemi dei documenti che minimizzino l’occupazione su disco e ottimizzano l’accesso di serie temporali relativi allo stesso oggetto di misura. Una discussione più approfondita su come modellare opportunamente i documenti la potete trovare qui.
I campi di applicazione sono quindi moltissimi. Si va dalle misurazione dei sensori nel campo dell’Internet of Things (IOT) fino ad arrivare alla tracciatura degli eventi di un sistema informativo. Nei database di esempio forniti in MongoDB Atlas troviamo il database sample_weatherdata. Nonostante la struttura dei documenti non rispecchi le indicazioni di modellazione delle serie temporali, è un ottimo esempio per esercitarsi con l’aggregation framework per estrarre statistiche relativamente al tempo.
Supponiamo di dover estrarre per ciascun intervallo di tempo le temperature minime e massime se ci sono state più di 10 rilevazioni. In questo caso dovremo inizialmente raggruppare per il campo ts e calcolare le misure di interesse. Il primo stage della pipeline di aggregazione risulterà quindi:
{$group: {
_id: "$ts",
minTemp: { $min: "$airTemperature.value"},
maxTemp: { $max: "$airTemperature.value"}
}
} Il risultato di questo stage sarà un insieme di documenti dove ciascuno rappresenta un istante temporale con le relative misure della temperatura. Non viene considerato però il numero di misurazioni, ossia di documenti, che appartengono a ciascun gruppo. Per poter escludere i documenti che non soddisfano la condizione richiesta dobbiamo inserire un ulteriore misura nello stage $group: il numero di elementi appartenenti a ciascun gruppo. Per far ciò basta inserire la misura count come visto nell’esempio precedente.
{$group: {
_id: "$ts",
minTemp: { $min: "$airTemperature.value"},
maxTemp: { $max: "$airTemperature.value"},
count: {$sum: 1}
}
} Il filtraggio in base al numero di documenti appartenenti a ciascun gruppo verrà effettuato mediante l’operatore $match.
{$match: {
c: {$gt:10}
}} La struttura di questa pipeline è molto simile a quella che si effettua nelle query SQL quando si effettua una GROUP BY e poi si inserisce l’operatore HAVING per filtrare il risultato. A differenza del linguaggio SQL ove è possibile usare funzione di aggregazione (min, max, avg, count, sum) nelle clausole di having e select, in MongoDB è necessario definire nello stage $group tutte le misure che verranno utilizzate negli stage successivi. Bisogna infatti ricordare che l’output di ciascun stage di un aggregation pipeline è un insieme di documenti che ricopriranno il ruolo di input per gli stage successivi.
Nell’esempio appena trattato si è usato direttamente il valore di un campo specifico per definire gli intervalli temporali. Questo è dovuto al fatto della distribuzione dei dati della collezione analizzata. In molti casi, però, è richiesto definire degli intervalli derivanti dal timestamp salvato nei documenti come ad esempio il giorno della settimana, il mese o addirittura l’anno. MongoDB offre la possibilità di estrarre queste informazioni dai timestamp in modo semplice ed inserirle nell’aggregation pipeline. Potremmo quasi paragonare questa proprietà ai processi di Extract, Transform, Load (ETL) tipici dei data warehouse. Vediamo di seguito un esempio basandoci sulla collezione sales del database sample_supplies.
Supponiamo di voler calcolare l’incasso totale e il numero di articoli venduti per ciascun mese. La collezione contiene nel campo saleDate solo il timestamp relativo al momento dell’acquisto. Bisogna pertanto estrarre da questo campo le informazioni necessarie per definire opportunamente gli intervalli.
Attenzione
Gli operatori temporali possono essere applicati solo su campi di tipo Date, Timestamp, e ObjectID. Inoltre, ciascun operatore estrae solo l'informazione per cui è stato definito. Ad esempio l'operatore $month estrarrà il valore numerico del mese, mentre $year l'anno. Pertanto se si vuole raggruppare per ciascun mese bisogna utilizzare sia il mese che l'anno. Diversamente mesi appartenenti ad anni diversi non verranno distinti.
Per utilizzare le informazioni del mese e dell’anno nelle analisi che andremo ad effettuare dobbiamo aggiungerle a ciascun documento della collezione. Non è però necessario eseguire un’operazione di update! Possiamo usare lo stage $addFields per inserire nuovi attributi a ciascun documento e rendere questa modifica disponibile solo all’interno della pipeline di aggregazione. In questo modo non andremo ad aumentare le dimensioni del nostro database con informazioni che possono essere calcolate in modo efficace quando sono necessarie, né tantomeno dovremo modificare le applicazioni che utilizzano il database per gestire in modo opportuno la nuova struttura dati. Il primo stage quindi risulterà il seguente:
{$addFields: {
month: { $month: "$saleDate" },
year: {$year: "$saleDate"}
}} I documenti in uscita da questo stage avranno una struttura simile a quella riportata qui sotto.

Poiché la richiesta è di calcolare alcune statistiche relative alla vendite, dobbiamo scomporre il vettore items. Questa operazione verrà eseguita mediante l’operatore $unwind.
{$unwind: {
path: "$items"
}} Ogni documento quindi rappresenterà la vendita di un singolo articolo. Le informazioni che sono state aggiunte all’inizio vengono conservate. Possiamo quindi raggruppare tutti di documenti appartenenti all’intervallo temporale di interesse.
Poiché non abbiamo definito un campo univoco che racchiuda sia il mese che l’anno, dobbiamo inserire come _id dell’operatore $group un documento costituito da entrambi i campi. Questa operazione è lecita e deve essere eseguita ogni volta che i gruppi di interesse sono determinati dalla combinazione dei valori di attributi diversi.
{$group: {
_id: {month: "$month", year: "$year"},
c: {$sum:1},
income: {$sum: "$items.price"}
} I documenti risultanti avranno la seguente struttura.



