
Come viso nell’articolo Clustering: un vero progetto per esplorare i dati, abbiamo utilizzato l’apprendimento automatico non supervisionato per segmentare/clusterizzare 192 quartieri della Carolina del Nord in base a diversi indicatori chiave del mercato immobiliare.
Alla fine del progetto, abbiamo esportato i dati e suggerito di usare tool come Tableau e Google Looker per visualizzare i risultati ottenuti mediante alcuni grafici. Una delle possibili visualizzazioni è il grafico Scatter Bubble, una tecnica eccellente per visualizzare i risultati della segmentazione. Consente, infatti, di proiettare i cluster su 3 dimensioni: gli assi x e y per le prime due dimensioni e la dimensione della bolla per la terza. Di seguito è riportata una possibile schermata della dashboard di Tableau.
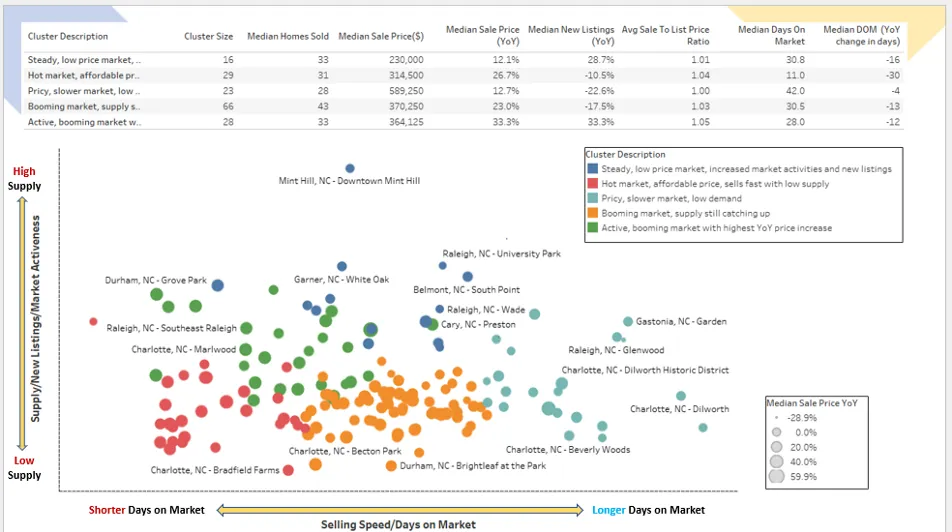
Sebbene Tableau sia uno strumento fantastico per la creazione di visualizzazioni interattive, è un po’ fastidioso passare da una piattaforma all’altra: addestrare modelli e creare segmenti in ambiente Python e poi visualizzare i risultati in un altro strumento. Inoltre, per uso professionale è a pagamento. Per questi motivi, in questa esercitazione vorrei mostrarvi come utilizzare Plotly Go (Graph Objects) di Python per creare lo stesso grafico interattivo con colori e tooltip personalizzati che possono soddisfare le vostre esigenze in questo caso d’uso.
Plotly Express vs Plotly Go
La libreria Plotly Python è una libreria di plottaggio interattiva e open-source che copre un’ampia gamma di tipi di grafici e casi d’uso di visualizzazione dei dati. Ha un wrapper chiamato Plotly Express che è un’interfaccia di livello superiore a Plotly.
Plotly Express è facile e veloce da usare come punto di partenza per creare le figure più comuni con una sintassi semplice, ma manca di funzionalità e flessibilità quando si tratta di tipi di grafici più avanzati o di personalizzazioni.
A differenza di Plotly Express, Plotly Go (Graph Objects) è un pacchetto di grafici di livello inferiore che generalmente richiede una maggiore quantità di codice, ma è molto più personalizzabile e flessibile. In questa esercitazione, utilizzeremo Plotly Go per creare un grafico interattivo a bolle di dispersione simile a quello creato in Tableau. È inoltre possibile salvare la codifica come modello per creare grafici simili in altri casi d’uso.
Leggere e preparare i dati
Alla fine del precedente progetto, abbiamo creato un frame di dati che contiene le metriche del mercato immobiliare per 192 quartieri del NC e i cluster assegnati (cluster_nbr) dall’algoritmo k-means. Leggiamo questi dati e diamo un’occhiata all’aspetto dei dati:
#Import libraries
import pandas as pd
import numpy as np
import plotly.graph_objects as go
#Read the cluster data
df_NC=pd.read_csv('.../df_NC.csv',index_col=[0])
Fields=[
'region',
'period_begin',
'period_end',
'period_duration',
'parent_metro_region',
'property_type',
'median_sale_price',
'median_sale_price_yoy',
'homes_sold',
'new_listings_yoy',
'median_dom',
'median_dom_yoy',
'avg_sale_to_list',
'cluster_nbr',
'0',
'1',
'2'
]
#Only select fields that are needed in this visualization
df_NC=df_NC[Fields]
df_NC.info()

Abbiamo 192 righe e 17 campi. Il campo “cluster_nbr” è l’etichetta del cluster che abbiamo assegnato a ciascun quartiere in base all’algoritmo k-means. Gli ultimi tre campi sono componenti principali derivate dalla PCA, che ci permetteranno di proiettare i nostri cluster su un grafico a dispersione, con le prime due componenti principali come assi x e y.
Rinominiamo anche alcune colonne per renderle più comprensibili. Inoltre, la colonna cluster_nbr è un numero intero, che non funzionerà in seguito nel nostro codice per produrre l’output desiderato. Pertanto, dovremo cambiare il suo tipo di dati in stringa.
#Rename fields to make them easier to understand
df = df_NC.rename({'region': 'Neighborhood', '0': 'PC1','1':'PC2','2':'PC3'}, axis=1)
df['cluster_nbr'] = df['cluster_nbr'].apply(str) #Change data type for cluster_nbr
df.head()


Aggiungere la descrizione del cluster
Ora che abbiamo letto e preparato i dati dei cluster, facciamo una rapida analisi per mostrare le statistiche riassuntive a livello di cluster. Questo ci aiuterà a capire le caratteristiche distinte di ogni cluster e ad aggiungere una descrizione significativa per ogni cluster (invece di etichette generiche per i cluster come 0,1,2,3 ecc.)
#Create summary statistics for clusters. Calucating medians for the following metrics at cluster level
df1=df.groupby(['cluster_nbr'])['cluster_nbr'].count()
df2=df.groupby(['cluster_nbr'])['homes_sold','median_sale_price','median_sale_price_yoy','new_listings_yoy','avg_sale_to_list','median_dom','median_dom_yoy'].median()
df_summary=pd.concat([df1, df2],axis=1)
df_summary.rename({'cluster_nbr': '# of Neighborhoods','homes_sold':'Median Homes Sold','median_sale_price':'Median Sale Price','median_sale_price_yoy':'Median Sale Price YoY','new_listings_yoy':'Median New Listings YoY','avg_sale_to_list':'Median Sale-to-List Ratio','median_dom':'Median Days on Market','median_dom_yoy':'Median Days on Market YoY (days)'}, axis=1)

Sulla base delle statistiche di sintesi, possiamo descrivere le caratteristiche di ciascun cluster. Ad esempio, il cluster “1” ha i giorni mediani di permanenza sul mercato più brevi e il secondo più alto aumento dei prezzi rispetto all’anno precedente, mentre il cluster “2” è un mercato relativamente costoso con il prezzo di vendita mediano più alto, ma con il maggior calo dei prezzi rispetto all’anno precedente. Inoltre, le case di questo cluster impiegano più tempo per essere vendute. Sulla base delle nostre osservazioni, possiamo aggiungere una colonna di descrizione del cluster al nostro set di dati:
#Add cluster description to the dataframe
def f(row):
if row['cluster_nbr'] == '0':
val = 'Steady, low price market with increased supply/new listings YoY'
elif row['cluster_nbr'] == '1':
val = 'Rising/hot market.Affordable price.Sells fast with decreased supply/new listings YoY'
elif row['cluster_nbr'] == '2':
val = '#Pricy,cool market. Sells slower than other segments.Relatively lower demand'
elif row['cluster_nbr'] == '3':
val = 'Booming market.Supply still catching up'
elif row['cluster_nbr'] == '4':
val = 'Active/booming market with highest YoY sales price increase'
else:
val = 'NA'
return val
df['cluster_desc']= df.apply(f, axis=1)
df.head()

Creare un grafico a dispersione con Plotly
Per familiarizzare con Plotly, creiamo innanzitutto un semplice grafico a dispersione standard con un paio di righe di codice, come mostrato di seguito.
#Create a standard scatter plot
fig = go.Figure()
fig.add_trace(go.Scatter(x = df["PC1"], y = df["PC2"],
mode = "markers"))
fig.show()
Il diagramma di dispersione di base proietta i 162 quartieri su un grafico bidimensionale. L’asse X è la prima componente principale (PC1) che rappresenta la metrica velocità di vendita/giorni sul mercato. L’asse delle Y è la seconda componente principale (PC2) che rappresenta la metrica offerta/nuovi annunci su base annua.

Quando si passa il mouse su ogni punto dei dati, il grafico mostra un tooltip con le coordinate x e y, per impostazione predefinita. Con un paio di righe di codice, abbiamo creato un grafico interattivo di base che è abbastanza comodo. Ora possiamo aggiungere altre funzionalità e personalizzazioni al grafico e renderlo più informativo. In particolare, personalizzeremo e perfezioneremo il grafico facendo le seguenti cose:
- Mostrare i punti di dati con colori personalizzati che rappresentano cluster diversi.
- Aggiungere la dimensione della bolla che rappresenta l'”aumento mediano del prezzo di vendita (a/a)” per ogni punto dati.
- Personalizzare il tooltip al passaggio del mouse per mostrare informazioni aggiuntive su ciascun punto di dati.
- Aggiungere il titolo del grafico, le etichette degli assi x e y, ecc.
Aggiungere personalizzazioni al grafico
Per aggiungere personalizzazioni come i colori dei cluster, le dimensioni delle bolle e i suggerimenti per il passaggio del mouse, è necessario aggiungere tre nuove colonne al frame di dati che assegnano questi “parametri di personalizzazione” a ciascun punto di dati.
Il codice seguente aggiunge una nuova colonna chiamata ‘colore’ al frame di dati. Per prima cosa definiamo una funzione chiamata ‘colore’ che assegna un codice colore unico (specificato da noi) a ogni cluster_nbr. Poi applichiamo questa funzione a ogni punto di dati nel frame di dati, in modo che ogni punto di dati abbia il proprio codice colore a seconda del cluster a cui appartiene.
#Define a function to assign a unique color code to each cluster.
#You can choose any color code you want by tweaking the val parameter
def color(row):
if row['cluster_nbr'] == '0':
val = '#0984BD'
elif row['cluster_nbr'] == '1':
val = '#E12906'
elif row['cluster_nbr'] == '2':
val = '#08E9E7'
elif row['cluster_nbr'] == '3':
val = '#E18A06'
elif row['cluster_nbr'] == '4':
val = '#0C861A'
else:
val = 'NA'
return val
#Apply the function to each data point in the data frame
df['color']= df.apply(color, axis=1)
df.head()

Aggiungeremo anche una nuova colonna chiamata “dimensione” a ciascun punto dati, che mostrerà la dimensione di ciascuna bolla. Vogliamo che la dimensione della bolla rappresenti l’aumento mediano del prezzo di vendita su base annua: più grande è la bolla, maggiore è l’aumento del prezzo di vendita rispetto allo stesso periodo dell’anno precedente.
Alcuni punti dati hanno valori negativi per la variabile variazione del prezzo mediano e si otterrà un errore quando si cercherà di utilizzare direttamente questa variabile per tracciare le dimensioni delle bolle. Pertanto, utilizziamo lo scaler min-max per scalare questa variabile e farla cadere tra 0 e 1 con tutti i valori positivi.
#Create the 'size' column for bubble size
from sklearn.preprocessing import MinMaxScaler
minmax_scaler=MinMaxScaler()
scaled_features=minmax_scaler.fit_transform(df[['median_sale_price_yoy']])
df['size']=pd.DataFrame(scaled_features)
df.head()

Infine, aggiungiamo una colonna ‘testo’ che ci consentirà di mostrare tooltip personalizzati quando si passa il mouse su ciascun punto di dati. Questo si può ottenere utilizzando un ciclo for mostrato nel codice seguente.
#Add 'text' column for hover-over tooltips
#You can customize what fields or information you want to show in tooltips in the code below
hover_text = []
for index, row in df.iterrows():
hover_text.append(('Cluster Description:<br>{cluster_desc}<br><br>'+
'Neighborhood: {Neighborhood}<br>'+
'Metro: {parent_metro_region}<br>'+
'Homes Sold: {homes_sold}<br>'+
'Median Sales Price: ${median_sale_price}<br>'+
'Median Sales Price YoY: {median_sale_price_yoy}<br>'+
'New Listings YoY: {new_listings_yoy}<br>'+
'Median Days on Market: {median_dom}<br>'+
'Avg Sales-to-Listing Price: {avg_sale_to_list}'
).format(
cluster_desc=row['cluster_desc'],
Neighborhood=row['Neighborhood'],
parent_metro_region=row['parent_metro_region'],
homes_sold=row['homes_sold'],
median_sale_price=row['median_sale_price'],
median_sale_price_yoy=row['median_sale_price_yoy'],
new_listings_yoy=row['new_listings_yoy'],
median_dom=row['median_dom'],
avg_sale_to_list=row['avg_sale_to_list']))
df['text'] = hover_text
df.head()

Inglobare tutte le personalizzazioni
Ora che le colonne delle personalizzazioni sono state aggiunte al data frame, possiamo creare una figura e aggiungere le personalizzazioni alla figura.
Nel codice qui sotto, creiamo prima un dizionario che contiene il data frame per ogni cluster. Quindi si crea una figura e si aggiunge la prima traccia che utilizza i dati del primo cluster. Si scorre il dizionario e si aggiungono le altre tracce (cluster) una alla volta alla figura e alla fine si tracciano tutti i cluster nella stessa figura.
# Dictionary with dataframes for each cluster
cluster_name=df["cluster_nbr"].unique()
cluster_data = {cluster: df.loc[df["cluster_nbr"] == cluster].copy()
for cluster in cluster_name}
#Create a figure
fig = go.Figure()
#Add color, hover-over tooltip text, and specify bubble size
for cluster_name, cluster in cluster_data.items():
fig.add_trace(go.Scatter(
x=cluster['PC1'], y=cluster['PC2'],
marker = dict(color=cluster['color']),
name=cluster_name, text=cluster['text'],
marker_size=cluster['size']
))
# Tune marker appearance and layout
sizeref = 2.*max(df['size'])/(18**2)
fig.update_traces(mode='markers', marker=dict(sizemode='area',
sizeref=sizeref, line_width=2))
fig.show()

Stile e formato del grafico
Abbiamo raggiunto l’obiettivo di personalizzare il grafico a dispersione di base con colori diversi per segmento, testo personalizzato nei suggerimenti e dimensioni specifiche delle bolle. Notiamo che nel tooltip alcune metriche sono mostrate con molti decimali, difficili da leggere. Alcune metriche potrebbero essere mostrate meglio in percentuale. Apportiamo quindi queste modifiche di stile per rendere i tooltip più facili da capire.
#Styling changes to reduce decimal places to 2
df['avg_sale_to_list'] = pd.Series([round(val, 2) for val in df['avg_sale_to_list']], index = df.index)
df['homes_sold'] = pd.Series([round(val, 0) for val in df['homes_sold']], index = df.index)
df['median_dom'] = pd.Series([round(val, 1) for val in df['median_dom']], index = df.index)
#Styling changes to change the data format to percentages
df['median_sale_price_yoy'] = pd.Series(["{0:.1f}%".format(val * 100) for val in df['median_sale_price_yoy']], index = df.index)
df['new_listings_yoy'] = pd.Series(["{0:.1f}%".format(val * 100) for val in df['new_listings_yoy']], index = df.index)
Aggiungeremo anche un titolo al grafico e le etichette degli assi. Ricordiamo che gli assi x e y sono due componenti principali che rappresentano la velocità di vendita e l’offerta/nuovi annunci su base annua, quindi etichettiamo gli assi in base a questi significati.
# Create figure
layout = go.Layout(
title_text='NC Neighborhoods Housing Market Segments',
title_x=0.5,
xaxis = go.XAxis(
title = 'Shorter Days on Market <-------------> Longer Days on Market',
showticklabels=False),
yaxis = go.YAxis(
title = 'Lower Supply <------------> Higher Supply',
showticklabels=False
)
)
fig = go.Figure(layout=layout)
for cluster_name, cluster in cluster_data.items():
fig.add_trace(go.Scatter(
x=cluster['PC1'], y=cluster['PC2'],
marker = dict(color=cluster['color']),
name=cluster_name, text=cluster['text'],
marker_size=cluster['size']
))
# Tune marker appearance and layout
sizeref = 2.*max(df['size'])/(18**2)
fig.update_traces(mode='markers', marker=dict(sizemode='area',sizeref=sizeref, line_width=2))
fig.update_layout(showlegend=False)
fig.show()

Ora abbiamo creato un grafico interattivo a bolle di dispersione in Python con Plotly! Come potete vedere, la creazione del grafico richiede un po’ di lavoro. Questo succede molto spesso quando si lavora su un caso d’uso reale poichè ci sono molti dettagli e sfumature a cui pensare e di cui occuparsi nella codifica per far sì che il grafico appaia esattamente come quello che avete in mente!


