
BigQuery permette di interrogare grandi moli di dati in pochissimo tempo. Essendo un servizio gestito da Google, l’utente non deve preoccuparsi configurare il database e/o l’architettura. Nonostante ciò, l’utente deve porre attenzione a come i dati vengono salvati e a come scrivere le query per ottenere il massimo delle prestazioni da parte di BigQuery. Bisogna infatti ricordare che il servizio è a pagamento e il costo dipende dalle risorse richieste.
In questo articolo analizzeremo le best practices per ridurre i costi e migliorare i tempi di risposta di BigQuery.
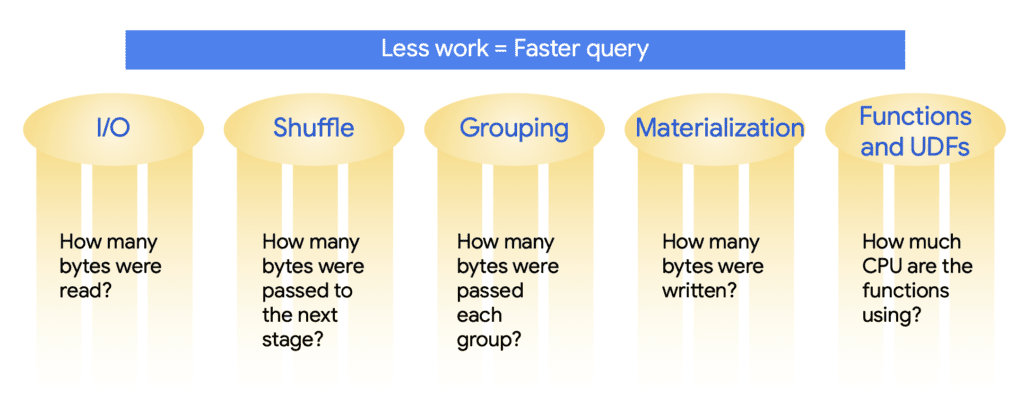
Esistono cinque aree chiave per l’ottimizzazione delle prestazioni in BigQuery e sono:
- Input/output: quanti byte sono stati letti dal disco
- Shuffling: quanti byte sono stati passati alla fase successiva di elaborazione della query
- Grouping: quanti byte sono stati passati ad ogni gruppo
- Materializzazione: quanti byte sono stati scritti permanentemente su disco
- Funzioni e UDF: quanto è computazionalmente costosa la query in termini di CPU
Come scrivere le query
Basandoci sulle cinque aree precedentemente introdotte, vediamo i “trucchi” da applicare nella scrittura delle query.
Per ridurre il numero di dati letti, non selezionate più colonne del necessario. Ciò significa evitare SELECT * tutte le volte che potete. Inoltre, inserite filtri nella clausola WHERE il prima possibile e spesso. In questo modo la mole di dati verrà ridotta.
Nel caso che abbiate un set di dati veramente enorme, considerate l’uso di funzioni di aggregazione approssimative invece di quelle regolari. Queste, infatti, sono molto più veloci da eseguire e richiedono meno CPU. Il contrappasso è che le statistiche saranno approssimate. In alcuni casi, però, questo aspetto può essere accettato.
Limitate l’utilizzo della clausola ORDER BY alla query più esterna, evitando l’ordinamento dei dati nelle fasi intermedie. Ad esempio, nelle tabelle temporanee definite mediante la clausola WITH, l’ordinamento non deve essere eseguito. Lo potete trovare in alcuni esempi solo associato alle finestre di aggregazione come visto nell’articolo BigQuery: WINDOWS analitiche.
Evitate il più possibile i JOIN. Qualora fossero necessari, mettete la tabella più grande a sinistra. Ciò aiuterà BigQuery ad ottimizzarla l’operazione. Se ci si dimentica, BigQuery probabilmente farà queste ottimizzazioni per voi, quindi potreste anche non vedere alcuna differenza.
Si possono usare i caratteri jolly nei suffissi delle tabelle per interrogare più tabelle, ma cercate di essere il più specifici possibile con questi caratteri jolly.
Gli attributi da inserire nella clausola della GROUP BY sono quelli che devono essere visualizzati senza funzioni di aggregazione nella SELECT. Attenzione però a scegliere gli attributi con pochi valori distinti.
Infine, è possibile partizionare le tabelle, come vedremo nella sezione successiva.
Di seguito riportiamo il cheat sheet delle best practises.

Partizionamento delle tabelle
Uno dei modi in cui puoi ottimizzare le tabelle nel tuo data warehouse è quello di ridurre il costo e la quantità di dati letti partizionando le tue tabelle.
Per esempio, supponiamo di aver partizionato la tabella mostrata nella figura sotto usando la colonna eventDate. BigQuery organizzerà il suo storage interno in modo tale che le date siano memorizzate in shard separati. Ogni partizione, ad esempio, conterrà i dati relativi ad un singolo giorno. Quando i dati vengono memorizzati, BigQuery assicura che tutti i dati all’interno di un blocco appartengano ad una singola partizione. Una tabella di partizione mantiene queste proprietà per tutte le operazioni che la modificano: query, istruzioni DML, istruzioni DDL, task di caricamento e di copia dati. Questo richiede che BigQuery mantenga un numero più elevato di metadati rispetto ad una tabella non partizionata.
Man mano che il numero di partizioni aumenta, la quantità di metadati aumenta. Il vantaggio, però, risulta nella riduzione di risorse richieste per determinate query. Ad esempio, se una query include nella clausola WHERE solo le date tra il 3 e il 4 gennaio, BigQuery dovrà leggere solo due quinti dell’intero set di dati. Ciò può portare ad un drastico risparmio di costi e tempo di esecuzione.

Ci sono due modalità principali per partizionare le tabelle in BigQuery. Quando si inseriscono per la prima volta i dati nella tabella di destinazione o utilizzando una colonna già presente. Nella figura qui sotto sono riportati i comandi per eseguire il partizionamento.

Il primo esempio mostra come si può creare una tabella che usa un partizionamento basato sul giorno al momento dell’ingest dei dati. BigQuery crea automaticamente nuove partizioni basate sulla data senza bisogno di ulteriore manutenzione. Inoltre, è possibile specificare il tempo di scadenza per i dati nelle partizioni.
Gli altri due casi, invece, usano una colonna esistente su una tabella già definita come chiave di partizionamento. Le colonne devono essere di tipo date, timestamp o una colonna sui cui si possano definire degli intervalli numerici di tipo intero. Nell’esempio riportato, si sta partizionando in base al campo customer_id definendo un intervallo di valori tra 0 e 100 con incrementi di 10.
Anche se è necessario mantenere più metadati assicurandosi che i dati siano partizionati globalmente, BigQuery può stimare più accuratamente i byte elaborati di una query prima di eseguirla. Questo calcolo dei costi fornisce un limite superiore al costo finale della query. Una buona pratica è quella di scrivere le query includendo sempre il filtro relativo alla partizione. Bisogna assicurarsi che il campo partizione sia isolato sul lato sinistro, poiché questo è l’unico modo in cui BigQuery può scartare rapidamente le partizioni non necessarie. Di seguito è riportato un esempio di come includere il riferimento alle partizioni.

Clustering
Oltre al partizionamento è possibile usare il clustering. Attualmente, BigQuery supporta il clustering solo su tabella partizionate. Questo tipo di raggruppamento dei dati può migliorare le prestazioni per alcuni tipi di query, come le query che usano clausole di filtro e quelle che aggregano i dati sull’attributo usato per definire il cluster. Una volta che i dati vengono scritti in una tabella di cluster, BigQuery ordina i dati utilizzando i valori nelle colonne di clustering. Questi valori vengono utilizzati per organizzare i dati, alcuni blocchi multipli e lo storage di BigQuery.
Quando si sottomette una query contenente un filtro sui dati delle colonne di clustering, BigQuery utilizza blocchi assortiti per eliminare le scansioni dei dati non necessari. Allo stesso modo, quando una query aggrega i dati in base ai valori delle colonne di clustering, le prestazioni vengono migliorate poiché i blocchi ordinati localizzano le righe con valori simili.
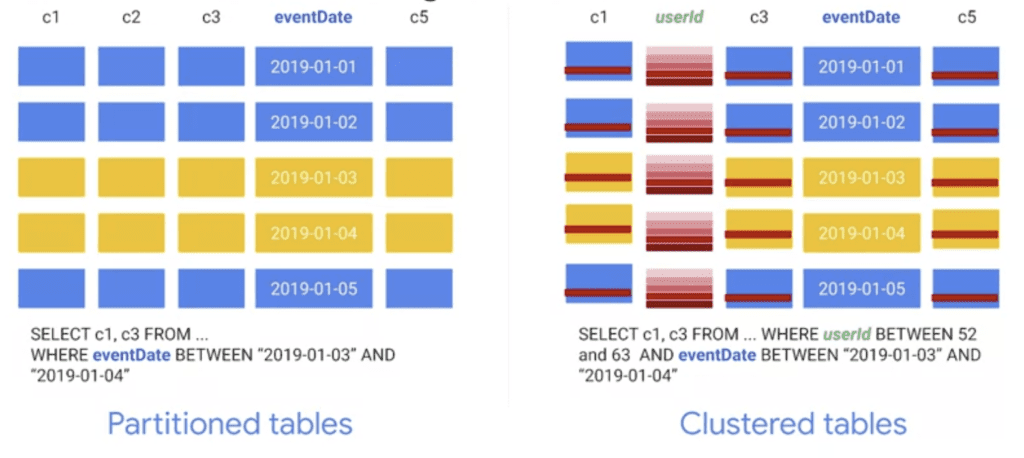
Nell’esempio riportato nella figura, le tabelle sono partizionate per eventDate e clusterizzate per userId. Dal momento che la query filtra i dati in base ad un intervallo di eventDate specifico, solo due delle cinque partizioni sono considerate. Inoltre, la query cerca gli utenti che hanno un identificativo in un intervallo specifico. Per questo motivo BigQuery può saltare all’intervallo di righe selezionate e leggere solo quelle righe per ciascuna delle colonne richieste nella query.
Il clustering viene impostato al momento della creazione della tabella. La creazione della tabella usata nell’esempio precedente viene definita con il seguente comando.
CREATE TABLE mydaset.mytable(
c1 NUMERIC,
userId STRING,
eventDate TIMESTAMP,
c5 GEOGRAPHY
)
PARTION BY DATE(eventDate)
CLUSTER BY userId
OPTIONS (
partition_expiration_days=3,
description='cluster')
AS SELECT * FROM mydaset.othertable; Oltre alla definizione di partizionamento e di clustering, l’istruzione specifica a BigQuery di far scadere le partizioni che hanno più di tre giorni.
Le colonne usate per il clustering localizzano i dati correlati. Quando si raggruppa una tabella usando più colonne, l’ordine delle colonne è importante poiché determina l’ordinamento dei dati stessi. In teoria, man mano che vengono eseguite modifiche sulla tabella, il grado di ordinamento dei dati comincia a indebolirsi, il che provoca un parzialmente ordinamento dei dati. Pertanto, se la tabella risulta parzialmente ordinata, le query che utilizzano le colonne di clustering potrebbero dover scansionare più blocchi rispetto a quando la tabella è completamente ordinata.
È possibile clusterizzare nuovamente i dati nell’intera tabella eseguendo una query che seleziona tutto e lo riscrive nella tabella stessa. Questa operazione però non è più necessaria!!! Infatti, BigQuery ora fa periodicamente il re-clustering automatico e gratuito.


