Ormai i chatbot hanno preso piede grazie al sempre più popolare ChatGPT. Questi però esistevano già in antecedenza, anche se le loro risposte erano molto limitate sia a livello di fluidità del testo restituito che alla loro limitata conoscenza. Ad oggi ormai tutti abbiamo usato ChatGPT per qualsiasi domanda, anche la più sciocca. Ma se volessimo avere un nostro chatbot che risponde sui nostri dati? Qui il discorso si fa più interessante. Infatti, anche se ChatGPT ha una conoscenza veramente vasta grazie ai dati su cui è stato costruito (praticamente tutto il web) ci sono sicuramente alcuni argomenti che non conosce.
Ad esempio, se siete un’azienda avrete dei documenti privati o dei regolamenti interni che non sono mai stati pubblicati sul web. A questo punto volete estrare alcune informazioni da queste risorse. Come potete fare? In questo caso dovremo costruire un chatbot che usa quei documenti come risorsa di conoscenza, ma che si basa su modelli di generazione del linguaggio naturale per fornire risposte sensate e fluide.
Esistono diversi modelli di generazione di linguaggio naturale (LLM) tra cui quello di ChatGPT. Se però non vogliamo spendere soldi ed esercitarci sui dati piccoli, possiamo usare alcuni modelli gratuiti. Questi non hanno sicuramente le performance di ChatGPT ma possono essere un ottimo punto di partenza per sviluppare il nostro chatbot. Tra gli LLM gratuiti, spicca Zephyr 7B Alpha di HuggingFace, insieme a Mistral 7B Instruct e Llama-2 7B Chat. Ciò che distingue Zephyr 7B Alpha è il suo approccio unico alla messa a punto attraverso la Direct Preference Optimization (DPO) (invece di RLHF), superando persino il modello Llama-2 70B, 10 volte più grande, su MT-Bench, un benchmark per la valutazione delle prestazioni conversazionali.
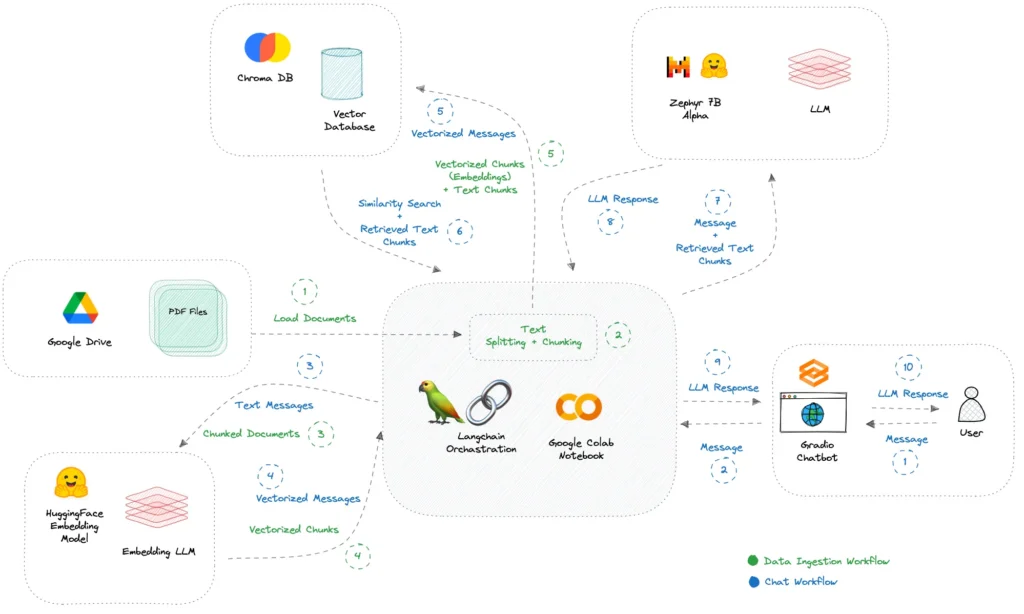
In questo articolo, vedremo passo passo il processo di creazione di un chatbot conversazionale utilizzando Zephyr 7B Alpha, Google Colab, ChromaDB, Langchain e Gradio. In questo modo, sarete in grado di caricare senza sforzo file PDF da Google Drive e di avviare conversazioni utilizzando la potenza di un Google Colab gratuito (GPU T4) e un’interfaccia di chat Gradio. Ecco i passi da seguire.
1. Inizializzare l’ambiente di lavoro
Per iniziare è necessario installare i pacchetti Python necessari usando pip.
#install required packages
!pip install -q transformers peft accelerate bitsandbytes safetensors sentencepiece streamlit chromadb langchain sentence-transformers gradio pypdf
Per evitare problemi di codifica dei caratteri vi suggeriamo di settare il tutto a UTF-8.
# fixing unicode error in google colab
import locale
locale.getpreferredencoding = lambda: "UTF-8"
Infine, bisogna importare tutte le librerie necessarie. In particolare, useremo Gradio che permette di creare interfacce web semplici e amichevoli, il tutto integrabile comodamente con Colab. Useremo anche langchain per acquisire le informazioni da documenti in formato pdf e i trasformers per aiutarci nella generazione del nostro modello.
# import dependencies
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, pipeline
import os
import gradio as gr
from google.colab import drive
import chromadb
from langchain.llms import HuggingFacePipeline
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain import HuggingFacePipeline
from langchain.document_loaders import PyPDFDirectoryLoader
from langchain.chains import ConversationalRetrievalChain
from langchain.memory import ConversationBufferMemory
2. Utilizzare il modello da HuggingFace
Come detto in precedenza non utilizzeremo modelli a pagamento ma uno gratuito. Pertanto, dobbiamo scaricare il modello Zephyr-7B-Alpha. Utilizzeremo la versione sharded, che consuma circa 5 GB di RAM sul notebook gratuito di Google Colab, garantendo un funzionamento fluido senza vincoli di memoria. Questo processo richiede in genere dai 5 ai 10 minuti quando si utilizza la GPU T4. Nel codice sottostante lascio anche alcuni altri modelli che possono essere utilizzati al posto di quello proposto.
# specify model huggingface mode name
model_name = "anakin87/zephyr-7b-alpha-sharded"
###### other models:
# "Trelis/Llama-2-7b-chat-hf-sharded-bf16"
# "bn22/Mistral-7B-Instruct-v0.1-sharded"
# "HuggingFaceH4/zephyr-7b-beta"
A questo punto definiamo alcune funzioni che ci serviranno per caricare il modello selezionato. La prima funzione ci aiuta a caricare il modello selezionato nella versione 4-bit.
# function for loading 4-bit quantized model
def load_quantized_model(model_name: str):
"""
:param model_name: Name or path of the model to be loaded.
:return: Loaded quantized model.
"""
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
quantization_config=bnb_config
)
return model
Successivamente definiamo una funziona per gestire il tokenizer.
# fucntion for initializing tokenizer
def initialize_tokenizer(model_name: str):
"""
Initialize the tokenizer with the specified model_name.
:param model_name: Name or path of the model for tokenizer initialization.
:return: Initialized tokenizer.
"""
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 # Set beginning of sentence token id
return tokenizer
A questo punto possiamo caricare il modello e inizializzare il tokenizer in base al modello selezionato.
# load model
model = load_quantized_model(model_name)
# initialize tokenizer
tokenizer = initialize_tokenizer(model_name)
# specify stop token ids
stop_token_ids = [0]
3. Caricare i documenti
Per caricare i documenti di nostro interesse, su cui il chatbot si baserà per le nostre risposte, è necessario collegare Google Drive a Google Colab. Supponiamo di aver caricato i file PDF con cui desideriamo interagire in una cartella (ad esempio, documents_colab) di Google Drive. Per stabilire una connessione tra Google Drive e Google Colab usiamo il seguente codice.
# mount google drive and specify folder path
drive.mount('/content/drive')
folder_path = '/content/drive/MyDrive/documents_colab/'
L’esecuzione di questo codice richiederà di concedere l’autorizzazione per l’accesso ai documenti del proprio account gmail. Seguite passo passo le schermate che man mano verranno mostrate per concedere tutti i permessi necessari.

4. Includere i documenti nel database vettoriale
Ora che i documenti sono accessibili in Google Colab, è possibile caricarli e segmentarli in pezzi di testo più piccoli. Useremo il database vettoriale Chroma DB per salvare i nostri documenti. Usando alcuni strumenti HuggingFace Embeddings e Langchain prepareremo opportunamente i nostri documenti per essere ospitati all’interno del nostro database. Ecco il codice per caricare i nostri file PDF.
# load pdf files
loader = PyPDFDirectoryLoader(folder_path)
documents = loader.load()
# split the documents in small chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) #Chage the chunk_size and chunk_overlap as needed
all_splits = text_splitter.split_documents(documents)
# specify embedding model (using huggingface sentence transformer)
embedding_model_name = "sentence-transformers/all-mpnet-base-v2"
model_kwargs = {"device": "cuda"}
embeddings = HuggingFaceEmbeddings(model_name=embedding_model_name, model_kwargs=model_kwargs)
#embed document chunks
vectordb = Chroma.from_documents(documents=all_splits, embedding=embeddings, persist_directory="chroma_db")
# specify the retriever
retriever = vectordb.as_retriever()
5. Costruire una pipeline RAG (Retrieval Augmented Generation)
Ora che abbiamo incluso i nostri documenti nel database vettoriale, è giunto il momento di costruire una pipeline RAG utilizzando HuggingFace e Langchain. Definiamo quindi la pipeline da usare e definiamo una funzione per gestire le conversazioni che andremo ad avere con il chatbot.
# build huggingface pipeline for using zephyr-7b-alpha
pipeline = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
use_cache=True,
device_map="auto",
max_length=2048,
do_sample=True,
top_k=5,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.eos_token_id,
)
# specify the llm
llm = HuggingFacePipeline(pipeline=pipeline)
# build conversational retrieval chain with memory (rag) using langchain
def create_conversation(query: str, chat_history: list) -> tuple:
try:
memory = ConversationBufferMemory(
memory_key='chat_history',
return_messages=False
)
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=retriever,
memory=memory,
get_chat_history=lambda h: h,
)
result = qa_chain({'question': query, 'chat_history': chat_history})
chat_history.append((query, result['answer']))
return '', chat_history
except Exception as e:
chat_history.append((query, e))
return '', chat_history
6. Creare l’interfaccia utente
Non ci resta a questo punto che costruire un’interfaccia utente che permetta di interagire con il nostro chatbot. In Gradio esiste già un blocco dedicato al chatbot al quale aggiungiamo una textbox per inserire la nostra richiesta e un bottone per cancellare la conversazione.
# build gradio ui
with gr.Blocks() as demo:
chatbot = gr.Chatbot(label='Chat with your data (Zephyr 7B Alpha)')
msg = gr.Textbox()
clear = gr.ClearButton([msg, chatbot])
msg.submit(create_conversation, [msg, chatbot], [msg, chatbot])
demo.launch()
Una volta eseguito il codice otterete un link che vi permetterà di accedere al vostro chatbot in una nuova scheda del browser. Potrete comunque interagire con l’interfaccia anche nel notebook di Colab. Di seguito è riportato un esempio di interazione che è stato fatto (considerate che i documenti era sui NoSQL database).

Conclusioni
Congratulazioni! Ora avete un chatbot AI completamente privato e operativo sul vostro notebook Google Colab, senza che i dati lascino l’ambiente del notebook.
Sebbene le risposte non sempre siano perfette, esse estraggono e astraggono abilmente le informazioni dal contesto fornito. Questo approccio offre un vantaggio significativo, consentendo di esplorare grandi quantità di dati testuali a costo zero, mantenendo e garantendo la privacy delle nostre informazioni.
Tuttavia, è essenziale riconoscere alcuni limiti di questa soluzione:
- Il modello può produrre risposte allucinate quando gli viene presentato un vocabolario specifico del dominio.
- I tempi di risposta possono variare da 15 a 30 secondi, a volte anche di più.


