Big Data, i.e., large collections of data, is increasingly common and of interest to businesses. Their processing and analysis is of fundamental importance. For this reason, in recent years, professional figures focused on this topic have been born.
Why is the skill of Big Data management and analysis so important and in demand professionally? According to research by McKinsey, by 2020, we will have 50 billion connected devices in the Internet of Things (IoT) industry. These devices will cause data production to double every two years. Unfortunately, however, only about one percent of the data generated today is actually analyzed according to McKinsey.
This aspect provides a great opportunity because there is a lot of knowledge and value in data that has not yet been analyzed. Therefore, the ability to develop applications that appropriately and efficiently manage and analyze Big Data is a skill that will open up many opportunities at both the business and personal level. Already, it is in high demand.
For this reason Google has designed several training courses to present its technologies and allow different professionals to increase their skills in Cloud management. For example, the Google Cloud Pro initiative has been launched in Italy. This includes three different free training courses for professionals offered by Google Cloud and TIM in collaboration with Fast Lane. Within each path there are webinars, Q&A sessions, on-demand courses and everything the student needs to arrive prepared for the certification exam.
What are the challenges you face when interacting with Big Data? One of them is, for example, migrating current workloads to an environment where all the data can be effectively analyzed. Developing tools that can offer interactive analysis of terabytes, or even petabytes, of data as historical data sets is also a very significant problem. Another challenge is building scalable pipelines that can handle streaming data, so that data-driven decisions can be made quickly and knowledgeably. Finally, perhaps the challenge of greatest interest is building machine learning models so that you not only react to the data, but are able to make predictive and forward-looking action predictions using the data.
In this article we illustrate some examples to understand both the complexity of Big Data problems and how Google has leveraged its technologies to improve the services it offers. Before looking at the case studies we need to make an introduction to the Google Cloud infrastructure.
Google Cloud Infrastructure
The Google Cloud infrastructure can be grouped into 5 macro blocks.
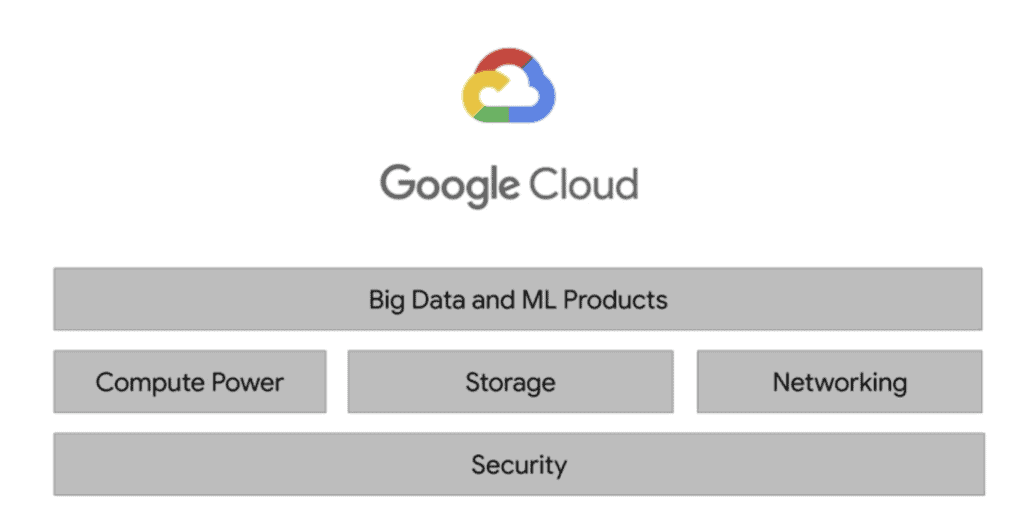
The base layer that covers all of Google’s applications, and therefore Google Cloud as well, is security. Above this layer, there is Compute Power, Storage and Networking. These enable processing, storage, analytics for business, data pipelines and machine learning models. Finally, Google has developed a top layer for managing big data and running Machine Learning processes in order to abstract the management and scalability of the infrastructure.
Running so many sophisticated Machine Learning models on large volumes of structured and unstructured data required a massive investment in computing power.
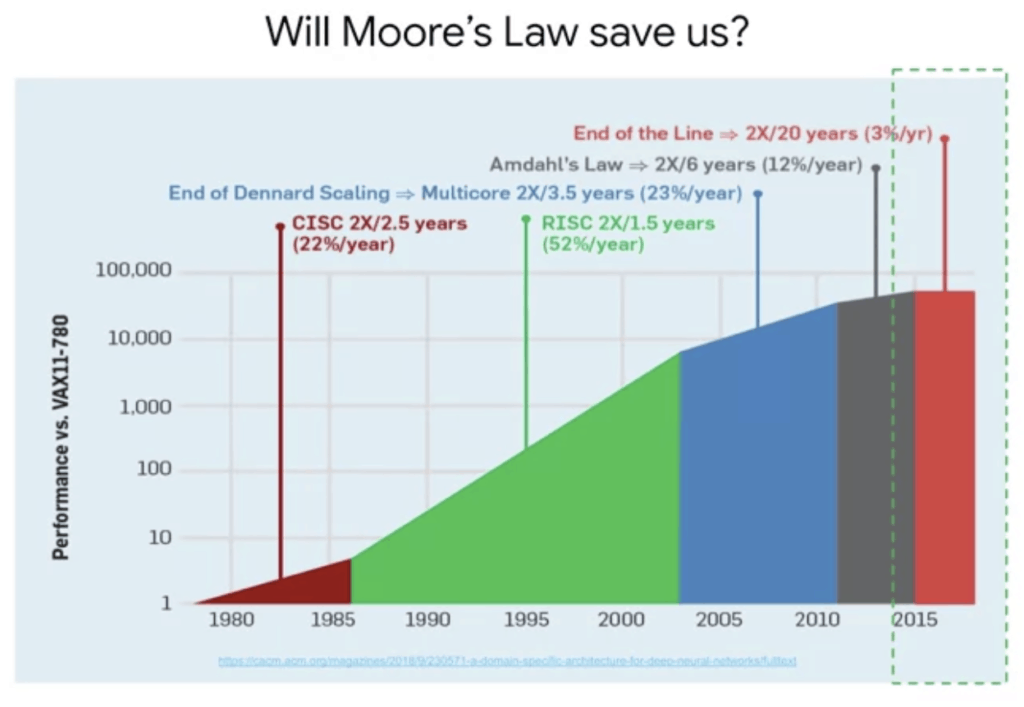
Google has been doing distributed computing for over 10 years for its own applications, and now, it has made that computing power available to users through Google Cloud. But simply scaling the number of servers in Google’s data centers is not enough. Historically, computing problems could be addressed through Moore’s Law.
«The complexity of a microcircuit, measured for example by the number of transistors per chip, doubles every 18 months (and then quadruples every 3 years).»
It essentially assumed the growth rate of computing power relative to hardware. For years, computing power has grown in accordance with this law. Therefore, it was assumed that one simply had to wait for it to reach the size to tackle complex problems.
In recent years, however, growth has slowed dramatically as chipmakers have run up against fundamental physical limits. Computing performance has reached a plateau.
One solution to this problem is to limit the power consumption of a chip, and you can do this by building Application-Specific Chips or ASICs.
Google has pursued this path by designing new types of hardware specifically for machine learning. The Tensor Processing Unit (TPU) is an ASIC specifically optimized for Machine Learning. It has more memory and a faster processor than traditional CPUs or GPUs. After working on the TPU for several years, Google has now made it available to other companies through Google Cloud.

Google Photos
Google Photos is the platform to collect photos and videos of users. With a simple Google account you can have a space, until some time ago unlimited, to store on the cloud your photos and videos in total safety. This tool, however, is not only useful to have a backup of your memories. In fact, over the years Google has developed some features that have increased the software’s usefulness. These features are based on the components of the Google Cloud platform.
Among the smart features introduced in Google Photos is automatic video stabilization. Let’s analyze this feature to understand the computing power provided by the platform and the size of the problem.
Data Sources
What data sources are needed as input for the model used by this new function?
Certainly the video data itself is needed, which is essentially the frames sorted by timestamps. But you also need other contextual data besides the video itself including time series about the position and orientation of the camera provided by the gyroscope and the movement of the camera lens.
How much data is required for the Google Photos Machine Learning model to compute and stabilize videos?
When considering the total number of values that represent a single frame of high-resolution video, the result is the product of the number of channel layers multiplied with the area of each layer, which with modern cameras can easily be in the millions. An eight-megapixel camera creates images of about eight million pixels each. Multiplied by three channels, you get more than 23 million data points per frame. Each second of video contains 30 frames. You can see how a short video represents over a billion input data points for the model. According to 2018 estimates, about 1.2 billion photos and videos are uploaded to the Google Photos service every day. This is 13 plus petabytes of photo data in total.
Similar discussion for YouTube, which has machine learning models for stabilizing videos and other models for automatically transcribing audio. YouTube’s data volume is over 400 hours of video uploaded every minute, or 60 petabytes every hour. But it’s not just about the size of each video in pixels.
Machine learning
The Google Photos team needed to develop, train, and deliver a high-performance machine learning model on millions of videos to ensure the model was accurate. To perform the model training, Google used a large network of data centers. Finally, small versions of the resulting model are deployed to the hardware of each individual smartphone.
The pre-trained models are provided by Google through the Cloud platform. Therefore, the Google Cloud user can exploit via APIs these models.
Google data center
Machine Learning algorithms developed by Google have not only been applied for user-facing services, but also to improve the efficiency of Google itself. Think of the number of data centers that Google has to keep cool and powered. These are monitored by a very large number of sensors that collect very different data.
Alphabet engineers saw this as an opportunity to ingest sensor data and train a machine learning model to optimize cooling better than existing systems could.
The model they implemented reduced cooling energy by 40 percent and increased overall energy efficiency by 15 percent.
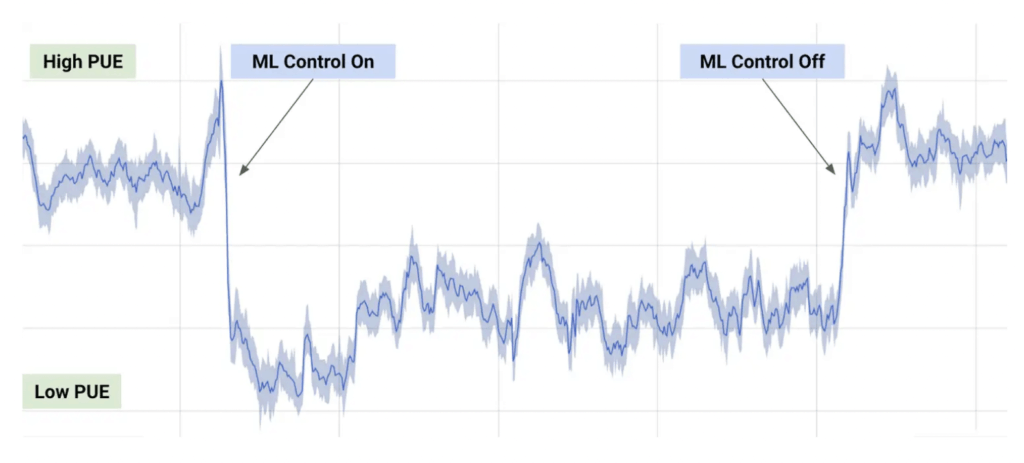
This example is particularly interesting because it involves a machine learning model trained on specialized machine learning hardware in a data center. The result is a model that tells the data center itself how much power it needs to use to perform machine learning of the very model it is using.
Case Studies
If you are interested in other examples I recommend visiting the dedicated Google Cloud page. Depending on your interests or the industry you work in, you will find extensive documentation of the problems and solutions that have been adopted.

