
Analizzare i dati è uno dei compiti principali dei data scientists. Esistono diversi librerie e tools che possono essere utilizzati a seconda delle nostre esigenze. Nel linguaggio Python una delle librerie maggiormente usate è Pandas. Pandas è una libreria open-source che fornisce una ricca collezione di strumenti di analisi dei dati. Gran parte delle sue funzionalità derivano dalla libreria NumPy. Ma perché viene utilizzato al posto di Numpy? Le sue caratteristiche permettono di:
- esplorare in modo efficiente i dati
- gestire in modo opportuno i dati mancanti
- supportare diversi formati di file come CSV, JSON, Excel, ecc.
- unire in modo efficiente diversi set di dati per un’analisi fluida
- leggere e scrivere i dati durante l’analisi
In questo articolo ci focalizzeremo come configurare il nostro ambiente di lavoro, le tipologie di strutture dato disponibili e come caricare diversi formati di dati. Iniziamo!
Configurazione dell’ambiente di lavoro
Il modo più rapido per utilizzare Pandas è scaricare e installare la distribuzione Anaconda. La distribuzione Anaconda di Python contiene Pandas e vari pacchetti per l’analisi dei dati.
Se avete installato Python e pip, eseguite il seguente comando dal terminale.
pip install pandas
Potete ovviamente usare Pandas anche in altri ambienti di lavoro adatti al vostro progetto. Potete usare, ad esempio, Jupyter notebook se volete provare il vostro codice inserendo anche un flusso di lavoro e dei commenti. Oppure, se necessitate di maggiore potenza di calcolo per le vostre analisi vi consigliamo di usare Google Colab.
Per iniziare a usare Pandas, è necessario importarlo:
import pandas as pd
In questo caso usiamo pd come alias per la libreria Pandas, che di solito è abbastanza usato dai programmatori. Uno volta importata la libreria possiamo iniziare a lavorarci. Esploriamo ora le strutture dati a disposizione.
Strutture dati
Pandas ha due strutture dati principali, Series e DataFrame. Queste due strutture di dati sono costruite su array NumPy, il che le rende veloci per l’analisi dei dati.
Una Series è una struttura di array monodimensionale etichettata che, nella maggior parte dei casi, può essere visualizzata come una colonna in un foglio Excel.
Un DataFrame è una struttura di array bidimensionale ed è per lo più rappresentato come una tabella.
Creare e recuperare i dati da una Series
Possiamo convertire strutture di dati Python di base come liste, tuple, dizionari e array NumPy in una serie Pandas. La serie ha etichette di riga che rappresentano l’indice.
Costruiamo una serie Pandas utilizzando il costruttore pandas.Series( data, index, dtype, copy) dove:
- data sono una lista, un ndarray, una tupla, ecc.
- index è un valore univoco e hashable
- dtype è il tipo di dati
- copy è una copia dei dati
import numpy as np
import pandas as pd
sample_list_to_series = pd.Series([300, 240, 160]) # pass in the python list into Series method
print(sample_list_to_series)
'''
0 300
1 240
2 160
dtype: int64
'''
sample_ndarray_to_series = pd.Series(np.array([90, 140, 80])) # pass the numpy array in the Series method
print(sample_ndarray_to_series)
'''
0 90
1 140
2 80
dtype: int64
'''
I valori della serie sono stati etichettati con i loro numeri di indice, cioè il primo valore con l’indice 0, il secondo con l’indice 1 e così via. Possiamo usare questi numeri di indice per recuperare un valore dalla serie.
print(sample_list_to_series[1])
# 240
print(sample_ndarray_to_series[2])
# 80
Quando si lavora con i dati delle serie, non è necessario lavorare solo con l’indice predefinito assegnato a ciascun valore. Possiamo etichettare ciascuno di questi valori come vogliamo, utilizzando l’argomento di index.
import numpy as np
import pandas as pd
sample_list_to_series = pd.Series([300, 240, 160], index = ['Ninja_HP', 'BMW_HP', 'Damon_HP'])
print(sample_list_to_series)
'''
Ninja_HP 300
BMW_HP 240
Damon_HP 160
dtype: int64
'''
sample_ndarray_to_series = pd.Series(np.array([90, 140, 80]), index = ['valx', 'valy', 'valz'])
print(sample_ndarray_to_series)
'''
valx 90
valy 140
valz 80
dtype: int64
'''
Quindi si possono recuperare i dati con i valori dell’etichetta dell’indice in questo modo:
print(sample_list_to_series['BMW_HP'])
# 240
print(sample_ndarray_to_series['valy'])
# 140
Si noti che con i dizionari non è necessario specificare l’indice. Poiché un dizionario Python è composto da coppie chiave-valore, le chiavi saranno utilizzate per creare l’indice dei valori.
sample_dict = {'Ninja_HP': 300, 'BMW_HP': 240, 'Damon_HP': 160}
print(pd.Series(sample_dict))
'''
Ninja_HP 300
BMW_HP 240
Damon_HP 160
dtype: int64
'''
Per recuperare più dati, si utilizza un elenco di valori di etichette di indice come questo:
print(sample_list_to_series[['Ninja_HP', 'Damon_HP']])
'''
Ninja_HP 300
Damon_HP 160
dtype: int64
'''
Creare e recuperare dati da un DataFrame
I dati in un DataFrame sono organizzati sotto forma di righe e colonne. È possibile creare un DataFrame da liste, tuple, array NumPy o da una serie. Tuttavia, nella maggior parte dei casi, il DataFrame viene creato da dizionari utilizzando il costruttore pandas.DataFrame( data, index, columns, dtype, copy), dove columns specifica le etichette delle colonne.
Creazione di un DataFrame da un dizionario di liste
Se il nostro dizionario contiene delle liste, queste devono avere la stessa lunghezza, altrimenti verrà lanciato un errore.
dict_of_lists = {'model' : ['Bentley', 'Toyota', 'Audi', 'Ford'], 'weight' : [1400.8, 2500, 1600, 1700]}
data_frame = pd.DataFrame(dict_of_lists)
print(data_frame)
'''
model weight
0 Bentley 1400.8
1 Toyota 2500.0
2 Audi 1600.0
3 Ford 1700.0
'''
Se non si passano specifiche sull’indice nel metodo DataFrame, l’indice predefinito viene passato con range(n), dove n è la lunghezza dell’elenco. Nella maggior parte dei casi, questo non è ciò che vogliamo, quindi creeremo un DataFrame indicizzato.
dict_of_lists = {'Model' : ['Bentley', 'Toyota', 'Audi', 'Ford'], 'Weight' : [1400.8, 2500, 1600, 1700]}
indexed_data_frame = pd.DataFrame(dict_of_lists, index = ['model_1', 'model_2', 'model_3', 'model_4'])
print(indexed_data_frame)
'''
Model Weight
model_1 Bentley 1400.8
model_2 Toyota 2500.0
model_3 Audi 1600.0
model_4 Ford 1700.0
'''
Creare un DataFrame da un dizionario di Series
Possiamo creare un DataFrame partendo da una serie.
dict_of_series = {'HP': pd.Series([300, 240, 160], index = ['Ninja', 'BMW', 'Damon']), 'speed' : pd.Series(np.array([280, 300, 260, 200]), index = ['Ninja', 'BMW', 'Damon', 'Suzuki'])}
print(pd.DataFrame(dict_of_series))
'''
HP speed
BMW 240.0 300
Damon 160.0 260
Ninja 300.0 280
Suzuki NaN 200
'''
Come potete notare, nella serie HP, non esiste un valore per l’’indice Suzuki in quanto la serie contiene solo 3 valori. Di conseguenza, nei risultati verrà aggiunto NaN senza sollevare nessun errore.
Selezione, aggiunta e cancellazione di colonne
Accedere a una colonna è semplice come accedere a un valore da un dizionario Python. Si passa il suo nome al DataFrame, che restituisce i risultati sotto forma di pandas.Series.
dict_of_lists = {'Model' : ['Bentley', 'Toyota', 'Audi', 'Ford'], 'Weight' : [1400.8, 2500, 1600, 1700]}
indexed_data_frame = pd.DataFrame(dict_of_lists, index = ['model_1', 'model_2', 'model_3', 'model_4'])
print(indexed_data_frame['Weight']) # get the weights column
'''
model_1 1400.8
model_2 2500.0
model_3 1600.0
model_4 1700.0
Name: Weight, dtype: float64
'''
È possibile, però, aggiungere una colonna a un DataFrame esistente utilizzando una nuova serie Pandas. Nell’esempio seguente, aggiungiamo il consumo di carburante per ogni moto nel DataFrame.
dict_of_series = {'HP': pd.Series([300, 240, 160], index = ['Ninja', 'BMW', 'Damon']), 'speed' : pd.Series(np.array([280, 300, 260, 200]), index = ['Ninja', 'BMW', 'Damon', 'Suzuki'])}
bikes_data_df= pd.DataFrame(dict_of_series)
#add column of fuel consumption
bikes_data_df['Fuel Consumption'] = pd.Series(np.array(['27Km/L', '24Km/L', '30Km/L', '22Km/L']), index = ['Ninja', 'BMW', 'Damon', 'Suzuki']) #add column of fuel consumption
print(bikes_data_df)
'''
HP speed Fuel Consumption
BMW 240.0 300 24Km/L
Damon 160.0 260 30Km/L
Ninja 300.0 280 27Km/L
Suzuki NaN 200 22Km/L
'''
Le colonne possono anche essere anche eliminate dal DataFrame. Per farlo, si possono usare le funzioni pop o del. Rimuoviamo le colonne velocità e consumo di carburante dal DataFrame delle moto.
# using pop function
bikes_data_df.pop('speed')
print(bikes_data_df)
'''
HP Fuel Consumption
BMW 240.0 24Km/L
Damon 160.0 30Km/L
Ninja 300.0 27Km/L
Suzuki NaN 22Km/L
'''
#using delete function
del bikes_data_df['Fuel Consumption']
print(bikes_data_df)
'''
HP
BMW 240.0
Damon 160.0
Ninja 300.0
Suzuki NaN
'''
Selezione, aggiunta e cancellazione di righe
Pandas dispone degli operatori loc e iloc, che possono essere utilizzati per accedere alle righe di un DataFrame.
iloc effettua una selezione basata sull’indice. Seleziona una riga in base alla sua posizione interna al DataFrame. Nel codice seguente, ad esempio, vengono selezionati i dati della seconda riga del DataFrame.
dict_of_series = {'HP': pd.Series([300, 240, 160], index = ['Ninja', 'BMW', 'Damon']), 'speed' : pd.Series(np.array([280, 300, 260, 200]), index = ['Ninja', 'BMW', 'Damon', 'Suzuki'])}
bikes_data_df= pd.DataFrame(dict_of_series)
bikes_data_df.iloc[1]
'''
HP 160.0
speed 260.0
Name: Damon, dtype: float64
'''
loc effettua una selezione basata invece sulle etichette. Seleziona una riga in base al valore dell’indice dei dati e non in base alla posizione. Nell’esempio successivo selezioniamo i dati dalla riga con l’etichetta BMW.
dict_of_series = {'HP': pd.Series([300, 240, 160], index = ['Ninja', 'BMW', 'Damon']), 'speed' : pd.Series(np.array([280, 300, 260, 200]), index = ['Ninja', 'BMW', 'Damon', 'Suzuki'])}
bikes_data_df= pd.DataFrame(dict_of_series)
bikes_data_df.loc['BMW']
'''
HP 240.0
speed 300.0
Name: BMW, dtype: float64
'''
Per aggiungere una nuova riga si utilizza la funzione append al DataFrame.
Attenzione!
Le nuove righe saranno sempre aggiunte alla fine del DataFrame originale.
sample_dataframe1 = pd.DataFrame([['Ninja',280],['BMW',300],['Damon',200]], columns = ['Model','Speed'])
sample_dataframe2 = pd.DataFrame([['Suzuki', 260], ['Yamaha', 180]], columns = ['Model','Speed'])
sample_dataframe1 = sample_dataframe1.append(sample_dataframe2)
print(sample_dataframe1)
'''
Model Speed
0 Ninja 280
1 BMW 300
2 Damon 200
0 Suzuki 260
1 Yamaha 180
'''
Leggere e analizzare i dati
Nella sezione precedente abbiamo visto le due principali strutture di dati di Pandas: Series e DataFrame. Negli esempi precedenti i dati li abbiamo inseriti direttamente da codice perché ci volevamo focalizzare sulle strutture dati e come leggerle e manipolarle. Difficilmente nei casi reali scriveremo i dati direttamente da codice, ma li dovremo leggere da fonti esterne.
Esistono numerosi formati in cui i dati possono essere memorizzati, ma in questo articolo esamineremo i seguenti tipi di formati di dati:
- File CSV (Comma Separated Values).
- File JSON.
- File di database SQL.
- File Excel.
Lettura e analisi dei dati da un file CSV
Utilizziamo il dataset del mercato immobiliare di Melbourne di Kaggle. Scaricheremo i dati nel nostro notebook in Colab utilizzando l’API fornita da Kaggle.
Per far ciò dovete prima accedere al vostro account Kaggle (createne uno se non ce l’avete) e dai settings del vostro profilo creare un’API Key.
A questo punto caricate il file kaggle.json che è stato automaticamente caricato nella cartella principale del notebook di Colab. Una volta caricato eseguite le seguenti istruzioni.
! mkdir ~/.kaggle
! cp kaggle.json ~/.kaggle/
! chmod 600 ~/.kaggle/kaggle.json
! kaggle datasets download anthonypino/melbourne-housing-market
! unzip melbourne-housing-market.zip
A questo punto abbiamo i dati a disposizione nel nostro ambiente di lavoro e possiamo caricarli. Per caricare i dati dal file CSV, si usa pd.read_csv().
melbourne_data = pd.read_csv('/content/Melbourne_housing_FULL.csv')
melbourne_data
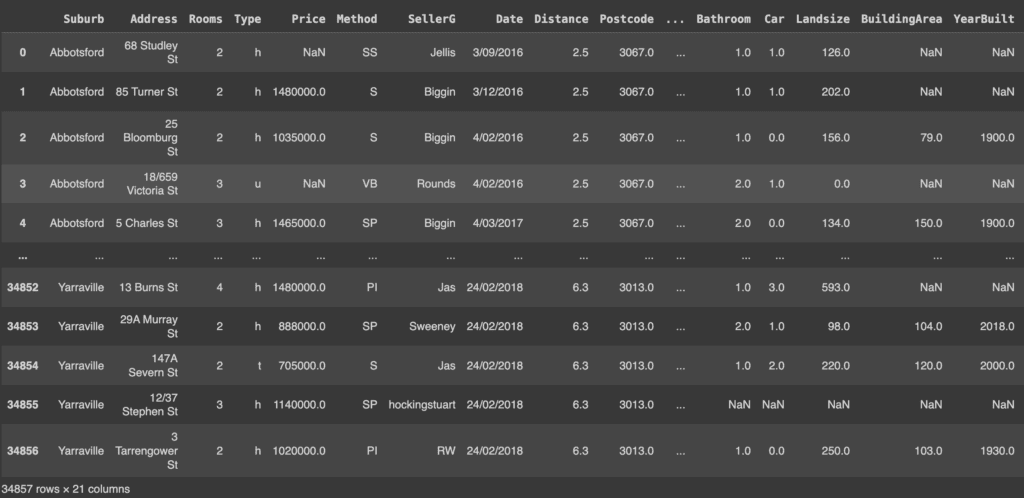
I risultati mostrano che Pandas ha creato la propria colonna di indici (la prima colonna visualizzata) nonostante il file CSV abbia la propria colonna di indici (l’attributo Suburb). Per far sì che Pandas utilizzi la colonna di indici del CSV, si deve specificare index_col.
melbourne_data = pd.read_csv('/content/Melbourne_housing_FULL.csv', index_col=0)
melbourne_data
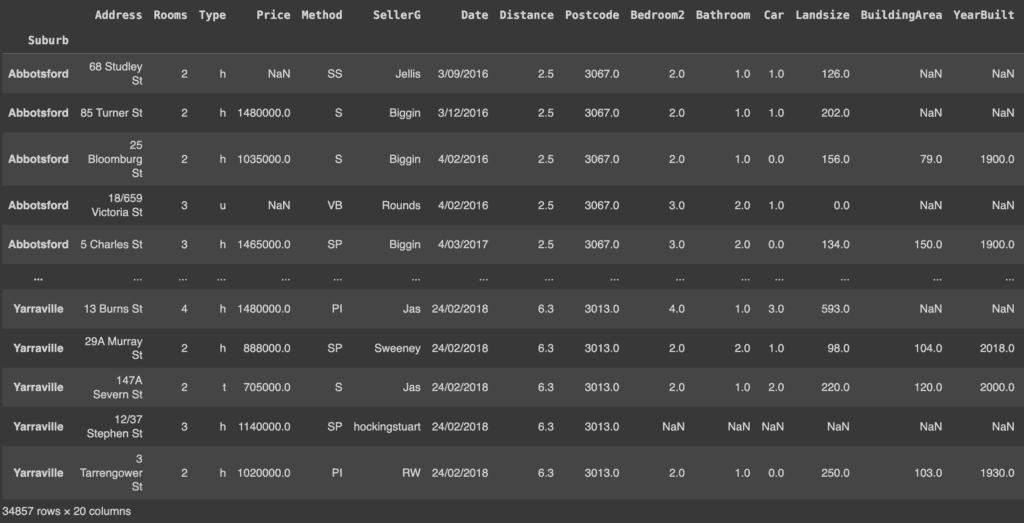
Se si desidera riportare l’indice a quello normale (0, 1… ecc.), è possibile utilizzare il metodo reset_index(). Questo metodo azzera l’indice del DataFrame e utilizza quello predefinito.
melbourne_data.reset_index()
Si noti che l’indice Suburb viene restituito come colonna. Tuttavia, negli esempi successivi procederemo con un DataFrame indicizzato.
Poiché i dati sono enormi e rappresentati in un DataFrame, Pandas restituisce solo le prime cinque righe e le ultime cinque righe. Possiamo verificare la dimensione dei dati utilizzando l’attributo shape.
print(melbourne_data.shape)
# (34857, 21)
Il DataFrame ha 34857 record (righe) e 21 colonne. È possibile esaminare qualsiasi numero di record utilizzando il metodo head(). Per impostazione predefinita, questo metodo visualizza i primi cinque record.
melbourne_data.head()
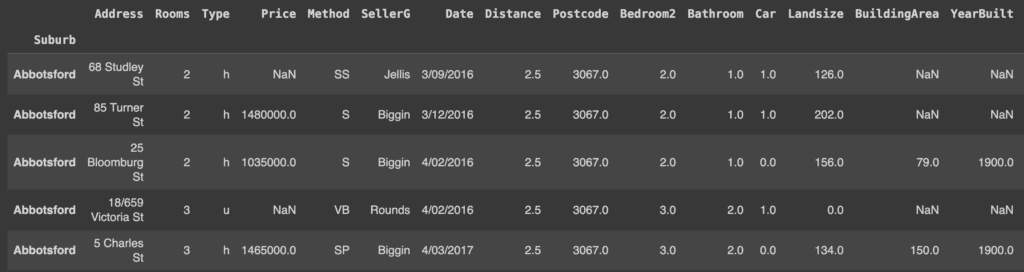
Se invece vogliamo visualizzare solo un numero predefinito di righe iniziali (ad esempio 3) useremo il seguente comando.
melbourne_data.head(3)

In modo analogo se vogliamo visualizzare le ultime righe del nostro DataFrame possiamo usare il metodo tail(). Per impostazione predefinita, restituisce gli ultimi cinque record, ma possiamo passare il numero di righe che vogliamo visualizzare.
melbourne_data.tail(3)

Per ottenere ulteriori informazioni sull’insieme di dati, è possibile utilizzare il metodo info(). Questo metodo stampa il numero di voci del dataset e il tipo di dati di ogni colonna.
print(melbourne_data.info())
'''
<class "pandas.core.frame.DataFrame">
Index: 34857 entries, Abbotsford to Yarraville
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Address 34857 non-null object
1 Rooms 34857 non-null int64
...
18 Regionname 34854 non-null object
19 Propertycount 34854 non-null float64
dtypes: float64(12), int64(1), object(7)
memory usage: 5.6+ MB
None
'''
Leggere i dati da un file JSON
In Pandas è possibile leggere i dati anche in formato json. Per questo scopo creiamo un semplice file JSON con Python e leggiamolo con Pandas.
import json
# creating a simple JSON file
car_data ={
'Porsche': {
'model': '911',
'price': 135000,
'wiki': 'http://en.wikipedia.org/wiki/Porsche_997',
'img': '2004_Porsche_911_Carrera_type_997.jpg'
},'Nissan':{
'model': 'GT-R',
'price': 80000,
'wiki':'http://en.wikipedia.org/wiki/Nissan_Gt-r',
'img': '250px-Nissan_GT-R.jpg'
},'BMW':{
'model': 'M3',
'price': 60500,
'wiki':'http://en.wikipedia.org/wiki/Bmw_m3',
'img': '250px-BMW_M3_E92.jpg'
},'Audi':{
'model': 'S5',
'price': 53000,
'wiki':'http://en.wikipedia.org/wiki/Audi_S5',
'img': '250px-Audi_S5.jpg'
},'Audi':{
'model': 'TT',
'price': 40000,
'wiki':'http://en.wikipedia.org/wiki/Audi_TT',
'img': '250px-2007_Audi_TT_Coupe.jpg'
}
}
jsonString = json.dumps(car_data)
jsonFile = open("cars.json", "w")
jsonFile.write(jsonString)
jsonFile.close()
Ora nel nostro folder abbiamo un file cars.json.
Per leggere i dati dal file JSON, si usa pd.read_json(). Pandas convertirà automaticamente l’oggetto dizionario in un DataFrame e definirà separatamente i nomi delle colonne.
pd.read_json('/content/cars.json')

Per analizzare i dati si possono applicare i metodi info, head() e tail(), come abbiamo fatto per i file CSV.
Leggere i dati da un database SQL
In molti contesti i dati sono disponibili in database relazionale. Per questo esempio, creiamo un database con python sqlite3. Pandas utilizza il metodo read_sql_query() per convertire i dati in un DataFrame.
Per prima cosa, ci colleghiamo a SQLite, creiamo una tabella e inseriamo i valori.
import sqlite3
conn = sqlite3.connect('vehicle_database')
c = conn.cursor()
# let's create a table and insert values with sqlite3
c.execute('''
CREATE TABLE IF NOT EXISTS vehicle_data
([vehicle_id] INTEGER PRIMARY KEY, [vehicle_model] TEXT, [weight] INTEGER, [color] TEXT)
''')
conn.commit()
# insert values into tables
c.execute('''
INSERT INTO vehicle_data (vehicle_id, vehicle_model, weight, color)
VALUES
(1,'Bentley',1400,'Blue'),
(2,'Toyota',2500,'Green'),
(3,'Audi',1600,'Black'),
(4,'Ford',1700,'White')
''')
conn.commit()
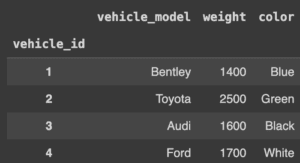
Nel database dei veicoli, abbiamo una tabella chiamata vehicle_data. Passeremo l’istruzione SELECT e la variabile conn per leggere da quella tabella.
cars_df = pd.read_sql_query("SELECT * FROM vehicle_data", conn)
cars_df.set_index('vehicle_id') # set index to vehicle_id
Lettura dei dati da un file Excel
È possibile anche leggere i dati da fogli Excel. Per creare un file excel direttamente da Python dobbiamo prima installare il modulo XlsxWriter mediante il seguente comando.
! pip install xlsxwriter
A questo punto possiamo creare il nostro file excel di esempio.
import xlsxwriter
workbook = pd.ExcelWriter('students.xlsx', engine='xlsxwriter')
workbook.save()
try:
df = pd.DataFrame({'stud_id': [1004, 1007, 1008, 1100],
'Name': ['Brian', 'Derrick', 'Ann', 'Doe'],
'Age': [24, 26, 22, 25]})
workbook = pd.ExcelWriter('students.xlsx', engine='xlsxwriter')
df.to_excel(workbook, sheet_name='Sheet1', index=False)
workbook.save()
except:
print('Excel sheet exists!')
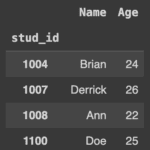
Abbiamo così creato un file Excel chiamato students.xlsx. Per leggere i dati da un file Excel si utilizza il metodo read_excel().
stud_data = pd.read_excel('/content/students.xlsx')
stud_data.set_index('stud_id')




Una risposta