Firebase: how to integrate a real-time database in Python
Firebase is a Google Cloud product that can. be used to build web applications quickly and easily. Among its features is the ability to create a NoSQL realtime database. Let’s find out how to interact with the database in a python program.
BigQuery and spreadsheets: how to integrate them?
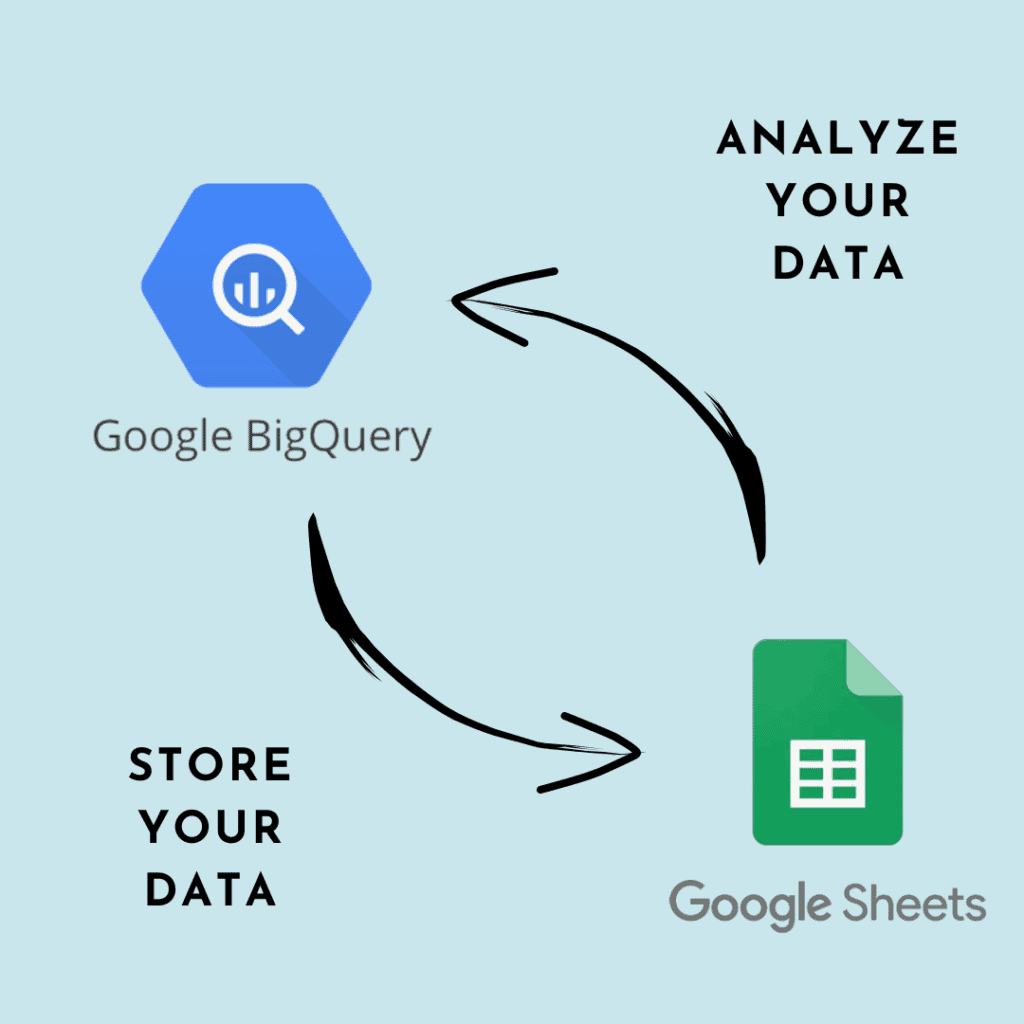
We all use Google services to manage email, write documents, create presentations, and do calculations. But have you ever wondered how these tools can be used to increase your work productivity? With Google’s simple spreadsheets and powerful BigQuery data warehouse, we can analyze large amounts of data without having to be an expert. Let’s find out how to easily integrate these two tools for our projects.
Google Cloud Storage: solution for data lakes

Google offers several solutions to implement a data lake. Of these, the most popular is Cloud Storage because of its versatility in data management and low cost. However, configuring the service requires some considerations depending on its use. Let’s discover its features and how to optimize performance and costs.
Data lakes: GCP solutions
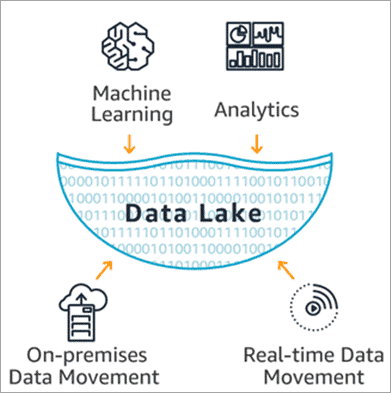
In the world of Big Data, raw data management plays a vital role. In most cases, it is not possible to load the data provided by different applications into data warehouses in order to create Machine Learning models or dashboards. Data lakes, i.e. raw data staging areas, play a key role to perform the necessary transformation pipelines. Let’s find out what solutions are offered by Google Cloud to implement a data lake.
BigQuery: performance optimization

Although BigQuery is a very good tool for querying terabytes, best practices should be adopted to improve performance. Let’s discover tricks for writing queries that execute quickly and save on execution costs. We also look at how you can optimize table storage through partitioning and clustering.
BigQuery: WINDOWS analytics

In many application scenarios, the statistics you need to extract refer to different groupings on the source data. By defining aggregation windows, you can calculate statistics within the same query. Moreover, if necessary, you can also provide different levels of data granularity through the ARRAY data type. Let’s discover these advanced features through two real-world examples.
BigQuery: GIS functions and Geo Vis

Geographic data plays a very important role in various analyses. BigQuery includes GIS functions in addition to the SQL standard to query, manipulate and analyze this kind of information. Let’s find out how to use and visualize them using Geo Vis.
BigQuery: WITH clause

Extracting data and analyzing it is a process that requires knowledge of data sources and the ability to write complex queries. BigQuery, Google’s database, makes it easy to access terabytes of data. Query writing, however, requires method. Let’s discover the WITH clause to increase the readability of our queries.
AutoML Vision: image classification

Developing classification models for unstructured data, such as images or text, is not an easy task. In many cases, very specific development skills are required. Let’s find out how it is possible, using AutoML Vision from Google Cloud, to create an image classification model without writing a line of code but only selecting images for our model.
Google Cloud: introduction to the platform
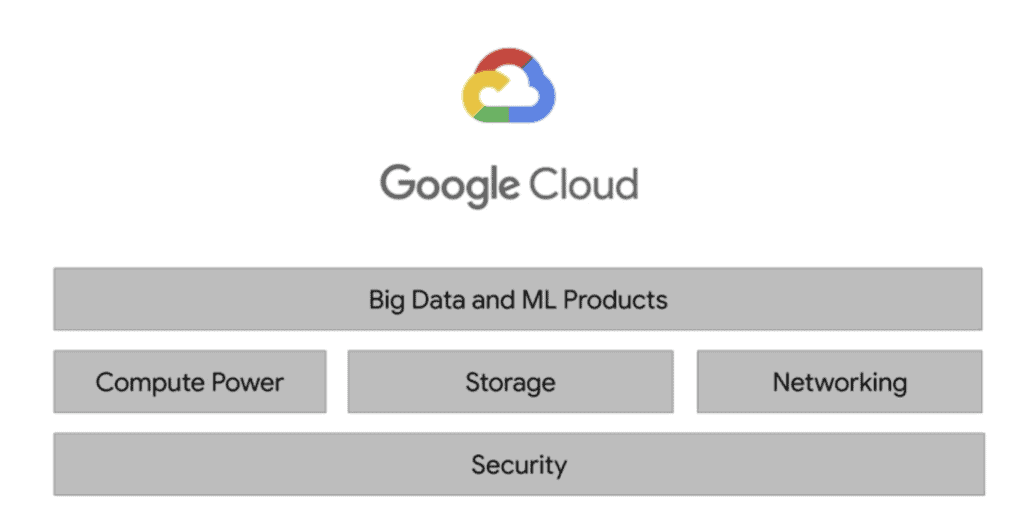
Big Data is one of the most profound and pervasive evolutions of the digital world. A trend that is destined to remain and to profoundly affect our lives and the way we do business. Managing them requires very powerful computing infrastructures. The big giants of the Web, including Google, Amazon and Microsoft, provide their data centers and platforms to address the challenges offered by Big Data. Let’s find out about the computing power provided by Google Cloud through some case studies.
